
How does machine learning apply to bioinformatics?
November 24, 2023I. Introduction
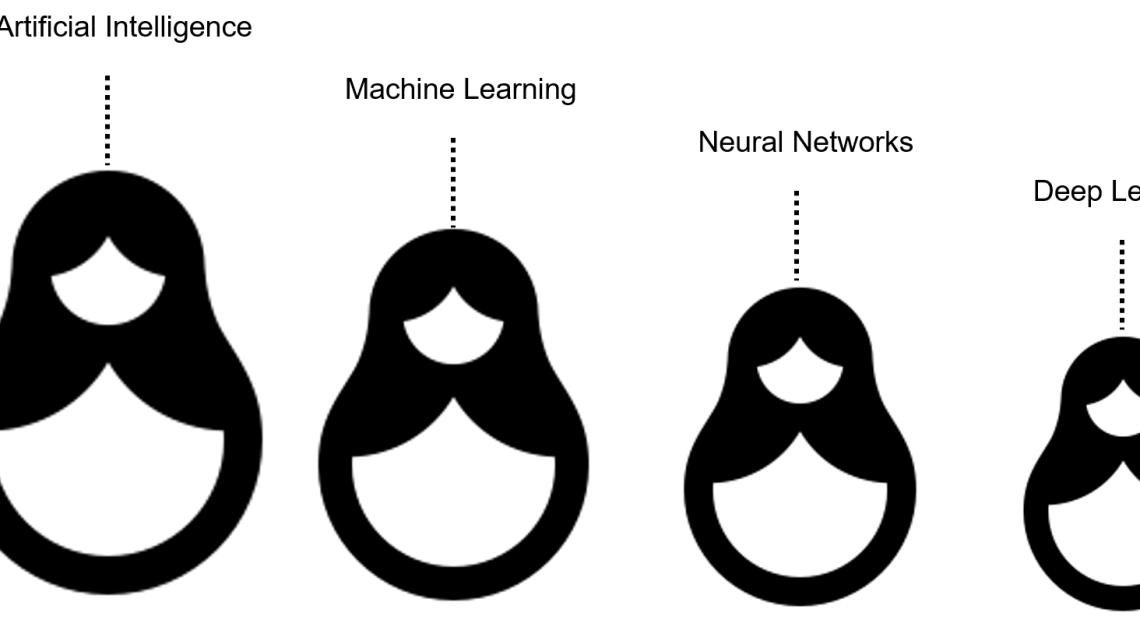
A. Intersection of Machine Learning and Bioinformatics:
- Defining Intersection: Highlighting the convergence point between machine learning and bioinformatics, where machine learning techniques are applied to analyze and extract insights from biological data.
- Synergy of Disciplines: Emphasizing the synergy created by integrating the computational power of machine learning with the complexities of biological systems.
B. Significance of Machine Learning in Biological Data Analysis:
- Enhancing Data Analysis: Discussing how machine learning brings computational efficiency and novel perspectives to the analysis of vast and complex biological datasets.
- Predictive Modeling: Showcasing the role of machine learning in predictive modeling, aiding in the identification of patterns and trends within biological data.
C. Overview of Applications and Advancements:
- Applications in Biology: Providing an overview of diverse applications, such as genomics, proteomics, and drug discovery, where machine learning has made significant contributions.
- Recent Advancements: Highlighting recent breakthroughs and advancements in the field, illustrating the continuous evolution and impact of machine learning on bioinformatics.
In summary, the introduction sets the context by exploring the intersection of machine learning and bioinformatics, emphasizing the significance of machine learning in biological data analysis, and providing an overview of applications and recent advancements in this interdisciplinary field.
II. Fundamentals of Machine Learning in Bioinformatics
A. Basics of Machine Learning Algorithms:
- Supervised Learning:
- Definition and Purpose: Explaining the concept of supervised learning where the algorithm is trained on labeled data to make predictions or classifications.
- Applications in Bioinformatics: Providing examples of how supervised learning is applied in biological contexts, such as predicting gene functions or classifying disease types.
- Unsupervised Learning:
- Definition and Purpose: Describing unsupervised learning, where the algorithm identifies patterns and structures in unlabeled data.
- Applications in Bioinformatics: Illustrating how unsupervised learning is used for clustering similar biological entities or discovering hidden patterns in large datasets.
- Semi-Supervised and Reinforcement Learning:
- Overview of Semi-Supervised Learning: Explaining the use of both labeled and unlabeled data in training algorithms.
- Reinforcement Learning in Bioinformatics: Discussing how reinforcement learning is employed in optimizing biological processes or making decisions in dynamic environments.
B. Types of Biological Data Analyzed:
- Genomic Sequences:
- Importance of Genomic Data: Discussing the critical role of genomic sequences in understanding genetic information.
- Machine Learning Applications: Providing examples of how machine learning is applied to analyze genomic data, such as predicting gene functions or identifying regulatory elements.
- Proteomic Profiles:
- Significance of Proteomic Data: Explaining the importance of studying protein expression and modifications.
- Machine Learning Applications: Highlighting how machine learning is utilized to analyze proteomic profiles for biomarker discovery or understanding protein-protein interactions.
- Metabolomic Data:
- Role of Metabolomics: Describing the study of metabolites and metabolic pathways in biological systems.
- Machine Learning Applications: Illustrating how machine learning techniques are applied to analyze metabolomic data for metabolic pathway prediction or biomarker identification.
In summary, this section provides a foundational understanding of machine learning algorithms, their applications in bioinformatics, and the types of biological data analyzed using these techniques.
III. Predictive Modeling in Genomic Medicine
A. Disease Prediction and Diagnosis:
- Identifying Biomarkers:
- Definition and Importance: Explaining what biomarkers are and their significance in disease identification.
- Machine Learning Applications: Providing examples of machine learning models used to identify and characterize biomarkers in genomic data.
- Case Studies: Highlighting specific instances where predictive modeling has successfully identified biomarkers for diseases.
- Early Detection of Diseases:
- Significance of Early Detection: Discussing the impact of early disease detection on treatment outcomes.
- Machine Learning Approaches: Describing how predictive models are employed for early detection based on genomic information.
- Success Stories: Presenting examples or studies where predictive modeling contributed to the early diagnosis of diseases.
B. Drug Discovery and Development:
- Virtual Screening:
- Overview of Virtual Screening: Defining virtual screening in the context of drug discovery.
- Role of Genomic Data: Explaining how genomic data is utilized in virtual screening processes.
- Machine Learning Algorithms: Discussing the machine learning algorithms used for predicting drug-target interactions.
- Compound Activity Prediction:
- Importance of Activity Prediction: Describing the significance of predicting the activity of chemical compounds.
- Applications in Drug Development: Providing examples of how machine learning models predict the activity of compounds in the drug development pipeline.
- Challenges and Opportunities: Discussing challenges and potential advancements in using predictive modeling for compound activity.
In summary, this section explores how predictive modeling, driven by machine learning, plays a crucial role in genomic medicine. It covers disease prediction, early diagnosis, and applications in drug discovery and development, emphasizing real-world applications and success stories.
IV. Genomic and Transcriptomic Data Analysis
A. Gene Expression Analysis:
- Clustering and Classification:
- Introduction to Gene Expression Analysis: Setting the context for analyzing gene expression data.
- Clustering Methods: Explaining how clustering techniques are applied to group genes or samples based on expression patterns.
- Classification Algorithms: Discussing machine learning algorithms used for classifying gene expression profiles.
- Identification of Co-Expression Modules:
- Co-Expression Networks: Defining co-expression networks and their relevance.
- Methods for Module Identification: Describing algorithms and approaches for identifying co-expression modules.
- Functional Implications: Discussing the functional insights gained from identifying co-expressed gene modules.
B. Variant Calling and Genomic Variation:
- Predicting Single Nucleotide Polymorphisms (SNPs):
- SNP Identification: Explaining the significance of SNPs in genomic variation.
- SNP Calling Algorithms: Describing computational methods and tools for predicting SNPs.
- Applications in Population Studies: Highlighting how SNP predictions contribute to population genetics studies.
- Structural Variant Detection:
- Structural Variations: Defining structural variants and their impact on the genome.
- Detection Methods: Explaining approaches, including sequencing and computational methods, for identifying structural variations.
- Disease Associations: Discussing how the detection of structural variants contributes to understanding genetic diseases.
In this section, the focus is on the computational analysis of genomic and transcriptomic data. It covers gene expression analysis, including clustering and co-expression modules, as well as variant calling for both single nucleotide polymorphisms (SNPs) and structural variants. The emphasis is on the methods, algorithms, and applications in biological research.
V. Proteomics and Structural Biology
A. Protein Structure Prediction:
- Homology Modeling:
- Overview of Homology Modeling: Introduction to the concept of homology modeling in predicting protein structures.
- Methodology: Explaining the steps involved in homology modeling, including template selection and model refinement.
- Applications: Discussing how homology modeling contributes to understanding protein structure and function.
- De Novo Structure Prediction:
- De Novo Methods: Introduction to de novo methods for predicting protein structures without relying on homologous templates.
- Challenges and Approaches: Discussing challenges in de novo structure prediction and approaches to address them.
- Advancements: Highlighting recent advancements in de novo protein structure prediction.
B. Functional Annotation of Proteins:
- Prediction of Protein Functions:
- Functional Annotation Methods: Overview of methods for predicting protein functions, including sequence-based and structure-based approaches.
- Enzyme Function Prediction: Discussing methods specific to predicting enzyme functions and catalytic activities.
- Biological Significance: Illustrating the importance of accurate functional annotation in understanding cellular processes.
- Annotation of Protein-Protein Interactions:
- Protein Interaction Networks: Introduction to protein-protein interaction networks and their role in cellular functions.
- Computational Methods: Describing computational methods for predicting and annotating protein-protein interactions.
- Implications in Systems Biology: Discussing how knowledge of protein-protein interactions contributes to systems biology.
This section focuses on computational approaches in proteomics and structural biology, covering the prediction of protein structures through homology modeling and de novo methods. Additionally, it explores functional annotation methods, including the prediction of protein functions and the annotation of protein-protein interactions. The aim is to provide insights into how computational tools enhance our understanding of protein structure and function.
VI. Integrative Multi-Omics Approaches
A. Integration of Genomic, Transcriptomic, and Proteomic Data:
- Holistic Understanding of Biological Systems:
- Conceptual Framework: Discussing the rationale behind integrating genomics, transcriptomics, and proteomics for a comprehensive view of biological systems.
- Synergy of Data Layers: Exploring how the combination of genomic, transcriptomic, and proteomic information provides a more nuanced understanding.
- Systems Biology Applications:
- Defining Systems Biology: Introducing the concept of systems biology as an interdisciplinary approach to studying complex biological systems.
- Case Studies: Highlighting specific examples where the integration of genomics, transcriptomics, and proteomics has led to significant insights.
- Network Analysis: Exploring how network-based approaches contribute to systems-level understanding.
This section delves into the significance of integrating genomic, transcriptomic, and proteomic data for a comprehensive understanding of biological systems. It emphasizes the synergy between different layers of omics data and explores applications in the field of systems biology. The goal is to showcase how an integrative multi-omics approach enhances our ability to decipher the complexities of biological processes.
VII. Biomarker Discovery and Personalized Medicine
A. Identification of Predictive Biomarkers:
- Patient Stratification:
- Defining Patient Stratification: Explaining the process of categorizing patients based on specific characteristics.
- Omics Data in Stratification: Discussing the role of genomic, transcriptomic, and proteomic data in identifying patient subgroups.
- Clinical Applications: Providing examples of patient stratification in various diseases.
- Treatment Response Prediction:
- Importance of Predictive Biomarkers: Highlighting how predictive biomarkers influence treatment decisions.
- Molecular Signatures: Exploring genomic and proteomic signatures associated with treatment response.
- Case Studies: Illustrating instances where personalized medicine based on biomarkers has led to improved treatment outcomes.
This section focuses on the pivotal role of biomarker discovery in advancing personalized medicine. It discusses the use of omics data in patient stratification and the prediction of treatment responses. Through case studies and examples, it aims to emphasize the transformative impact of biomarker identification on tailoring medical treatments to individual patients.
VIII. Challenges in Applying Machine Learning to Bioinformatics
A. Data Quality and Preprocessing:
- Addressing Noise and Variability:
- Sources of Noise: Identifying sources of noise in biological data, such as experimental errors and biological variability.
- Data Cleaning Techniques: Discussing methods for noise reduction and data cleaning in bioinformatics datasets.
- Standardization of Biological Data:
- Data Harmonization: Highlighting the challenges in integrating diverse datasets and the need for standardization.
- Best Practices: Discussing strategies for achieving standardization and ensuring data quality in bioinformatics.
B. Interpretability and Explainability:
- Understanding ML Model Outputs:
- Black-Box Models: Discussing challenges associated with the lack of interpretability in certain machine learning models.
- Model Output Interpretation: Exploring methods to interpret and validate the outputs of machine learning models in bioinformatics.
- Importance in Clinical Decision-Making:
- Clinical Relevance: Emphasizing the critical role of interpretability in the context of clinical decision-making.
- Regulatory Considerations: Discussing the importance of explainability in meeting regulatory standards for medical applications.
This section delves into the challenges encountered when applying machine learning to bioinformatics, with a specific focus on data quality, preprocessing, and the interpretability of machine learning model outputs. It aims to provide insights into addressing these challenges for more effective and reliable applications in the field.
IX. Future Trends and Innovations
A. Advanced Machine Learning Techniques:
- Deep Learning in Bioinformatics:
- Neural Network Architectures: Exploring advanced deep learning architectures such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs).
- Applications: Discussing the expanding role of deep learning in various bioinformatics applications, including image analysis, sequence prediction, and structure prediction.
- Reinforcement Learning in Biological Systems:
- Introduction to Reinforcement Learning: Providing an overview of reinforcement learning principles.
- Biological Applications: Exploring potential applications of reinforcement learning in simulating and understanding biological systems, such as protein folding.
This section explores the evolving landscape of machine learning in bioinformatics, focusing on cutting-edge techniques like deep learning and reinforcement learning. It aims to provide insights into the future directions of machine learning applications in the biological sciences, showcasing innovative methods and their potential impact on bioinformatics research.
X. Ethical Considerations
A. Privacy and Security Concerns:
- Handling Sensitive Health Data:
- Privacy Regulations: Exploring key regulations (e.g., GDPR, HIPAA) that govern the handling of health data.
- Anonymization and Pseudonymization: Discussing methods to protect individual identities while preserving data utility.
- Compliance with Ethical Guidelines:
- Ethical Review Boards: Highlighting the role of institutional review boards (IRBs) in overseeing research involving human subjects.
- Informed Consent: Emphasizing the importance of obtaining informed consent from study participants, ensuring transparency in data usage.
This section delves into the ethical considerations surrounding the use of bioinformatics data, particularly in the context of privacy and security. It addresses the challenges of handling sensitive health information and emphasizes the need for compliance with ethical guidelines and regulations to safeguard both researchers and study participants.
XI. Collaboration between Biologists and Data Scientists
A. Importance of Interdisciplinary Teams:
- Bridging the Gap between Biology and Data Science:
- The Synergy: Highlighting the complementary skills of biologists and data scientists in addressing complex biological questions.
- Breaking Silos: Encouraging collaboration to integrate diverse perspectives and methodologies.
- Successful Case Studies:
- Interdisciplinary Research Projects: Showcasing examples where collaborative efforts have led to significant advancements.
- Impactful Outcomes: Illustrating how joint initiatives have contributed to breakthroughs in biological research.
This section emphasizes the significance of fostering collaboration between biologists and data scientists, recognizing the unique contributions each discipline brings to the table. It explores the benefits of interdisciplinary teams in tackling intricate biological challenges and provides real-world case studies to highlight successful collaborative endeavors.
XII. Conclusion
A. Transformative Impact of Machine Learning in Bioinformatics:
- Recapitulating the profound influence of machine learning on advancing bioinformatics.
- Notable Achievements: Summarizing key accomplishments and breakthroughs enabled by machine learning applications.
B. Continuous Advancements and Collaborative Opportunities:
- Acknowledging the dynamic nature of the field and the need for continuous innovation.
- Future Collaborations: Encouraging ongoing partnerships between biologists, data scientists, and other stakeholders.
This concluding section encapsulates the transformative impact of machine learning in the realm of bioinformatics, emphasizing the continuous evolution of the field and the collaborative opportunities that lie ahead. It serves as a reflection on the journey covered in the document, highlighting the ongoing advancements and the potential for future collaborative endeavors.
Related posts:
![How to extract FASTA sequences from a file using a list of headers provided in another file]()
How to extract FASTA sequences from a file using a list of headers provided in another file
bioinformatics![genomics]()
Exploring Systems and Computational Biology: A Comprehensive Overview
bioinformatics![data-science]()
Getting Started with Machine Learning Using Orange Data Mining
A.I![bioinformatics-schoolstudents-carrerguide]()
The ABCs of Bioinformatics: Teaching Kids About DNA and Technology
bioinformatics![Omics data analysis]()
Step-by-Step Guide to Convert SAM to BAM
bioinformatics![neurobiology]()
Advanced Topics in Neurobiology for Bioinformatics
bioinformatics![apple-vision-pro-bioinformatics]()
How Apple Vision Pro Could Transform Bioinformatics
bioinformatics![bioifnormatics-2023]()
What's Next in Bioinformatics: 2023 Innovations in AI, Genomics, and Healthcare
A.I![Quantum_Computing_bioinformatics-omicstutorials]()
The Quantum Leap in Bioinformatics and Structural Biology
bioinformatics![IOT-healthcare]()
How AI, IoT, Big Data, and Blockchain Are Transforming Our World
A.I![3Dstructureofprotein-deepmind]()
Structural Bioinformatics
bioinformatics![engineeringgraphics]()
Engineering Graphics and Design
bioinformatics![will bioinformatics replace by AI]()
Revolutionizing Bioinformatics for Beginners: A Journey with ChatGPT
A.I![CRISPR-COVID-19]()
CRISPR-DIPOFF: A Deep Learning Breakthrough in Off-Target Predictions for CRISPR-Cas9
bioinformatics![remotecomputer-bioinformatics]()
Step-By-Step Docker Installation on Windows and Linux
bioinformatics![Introduction to Genomic Analysis]()
Introduction to Genomic Analysis
genomics
















