
The Evolution of Bioinformatics: A Journey Through Time
February 22, 2025Introduction
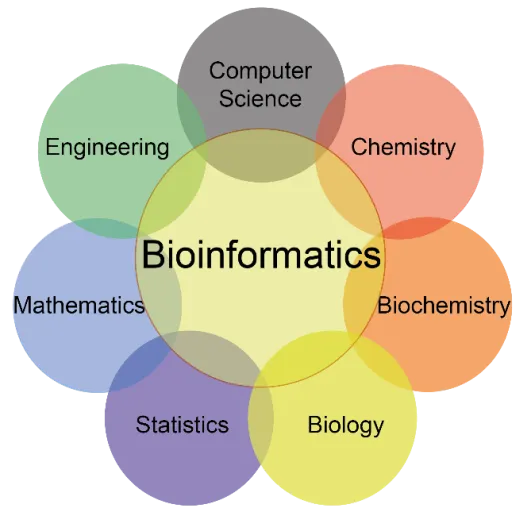
Bioinformatics has undergone a remarkable transformation since its inception, emerging as an indispensable discipline in biological research. Though often perceived as a recent innovation, its roots extend over half a century to an era when DNA analysis was still in its infancy and computers were far from the powerful machines they are today. As an interdisciplinary field, bioinformatics integrates biology, chemistry, computer science, information engineering, mathematics, and statistics, enabling scientists to manage and interpret vast amounts of biological data, ultimately accelerating progress in multiple research domains.
Initially focused on applying computational techniques to protein sequence analysis, bioinformatics has evolved alongside technological advancements and the increasing complexity of biological research. Today, it plays a crucial role in analyzing biological data, developing computational methodologies, and creating software tools that facilitate breakthroughs in genomics, proteomics, and metabolomics. As a result, bioinformatics has revolutionized the way biology and information technology interact, blurring the boundaries between the two disciplines.
The field’s history reflects humanity’s relentless curiosity and commitment to deciphering life’s complexities. With the continuous influx of new biological data, bioinformatics continues to push scientific frontiers, making significant contributions to medicine, genetics, agriculture, and numerous other fields. As bioinformatics advances further, its role in solving global challenges will only grow in significance.
Foundations of Bioinformatics
Molecular Biology and Chemistry
Bioinformatics is deeply rooted in molecular biology and chemistry. As early as the 1960s, researchers began leveraging computational techniques to analyze protein sequences. These early efforts laid the foundation for de novo sequence assembly and the development of biological sequence databases. The rapid expansion of protein biochemistry data necessitated the creation of advanced computational approaches capable of handling the increasing complexity of molecular interactions.
Mathematics and Statistics
Mathematics and statistics have always been integral to bioinformatics. The study of biological sequences—DNA, RNA, and proteins—relies on probabilistic models and statistical frameworks. Early on, substitution models were developed to estimate the likelihood of one nucleotide or amino acid replacing another over evolutionary time. With time, sophisticated statistical methodologies were introduced to address a wide array of challenges, including gene expression analysis, genome annotation, and evolutionary relationship inference.
Computer Science and Engineering
The exponential growth of molecular data in the 1960s underscored the limitations of manual analysis. This realization spurred the adoption of computers, enabling researchers to analyze vast datasets, develop efficient algorithms, and construct databases for biological information storage and sharing. Since its inception, bioinformatics has been an inherently interdisciplinary field, drawing on synergies between molecular biology, chemistry, mathematics, statistics, and computer science. This convergence has led to the development of powerful computational tools, revolutionizing our understanding of living organisms.
Early History and Pioneers
Paulien Hogeweg and Ben Hesper
Dutch theoretical biologists Paulien Hogeweg and Ben Hesper played a pivotal role in shaping bioinformatics in the early 1970s. They first coined the term “bioinformatics” to describe the study of information processes in biological systems. Their contributions, including cellular automata models, facilitated a deeper understanding of pattern formation in nature and laid the groundwork for computational biology.
Emile Zuckerkandl and Linus Pauling
In the early 1960s, Emile Zuckerkandl and Linus Pauling introduced the concept of the molecular clock, a groundbreaking method for estimating evolutionary divergence based on genetic differences. This innovation provided a foundation for computational sequence comparison and phylogenetic analysis, fundamental aspects of modern bioinformatics.
Needleman and Wunsch
In 1970, Saul B. Needleman and Christian D. Wunsch developed the Needleman-Wunsch algorithm, a pioneering sequence alignment method. This global alignment algorithm remains a cornerstone of bioinformatics, forming the basis for numerous subsequent sequence comparison techniques.
Development of Tools and Techniques
DNA and RNA Analysis
The advent of DNA sequencing techniques, such as Sanger and Maxam-Gilbert sequencing, marked a turning point in bioinformatics. However, these early methods were labor-intensive and low-throughput. The emergence of next-generation sequencing (NGS) technologies revolutionized the field by enabling massive data generation, necessitating sophisticated computational tools for data management and analysis.
- Key sequence databases: GenBank, RefSeq, and EMBL.
- Alignment algorithms: Needleman-Wunsch, Smith-Waterman, CLUSTAL, and MUSCLE.
- Software packages: Biopython and Bioconductor.
Protein Sequence and Structure Analysis
Early protein analysis relied on Edman degradation, but mass spectrometry has since become the dominant technique. Computational tools enable sequence alignment, functional annotation, and structural predictions.
- Protein sequence database: UniProt.
- Structural database: Protein Data Bank (PDB).
- Molecular modeling tools: MODELLER and I-TASSER.
- Molecular dynamics simulation software: GROMACS and NAMD.
Software and Algorithms
A plethora of computational tools address bioinformatics challenges, including:
- Phylogenetic tree construction: MEGA, PhyML.
- Protein docking: HADDOCK, ZDOCK.
- Gene expression analysis: Cufflinks, DESeq2.
Growth of Bioinformatics Databases
Sequence Databases
Sequence databases serve as fundamental resources for molecular biology research. Examples include:
- GenBank: A public repository for annotated nucleotide sequences.
- RefSeq: A curated reference dataset.
- UniProt: The authoritative protein sequence and function database.
Protein Structure and Interaction Databases
To facilitate protein research, several databases catalog protein structures and interactions:
- PDB: Houses experimentally determined macromolecular structures.
- InterPro: Provides insights into protein families and domains.
- STRING: Aggregates known and predicted protein-protein interactions.
Genomics and Comparative Genomics Databases
Advances in genomics necessitated specialized databases:
- Ensembl: Provides genome annotation for various species.
- NCBI Genome: Centralized access to genome-scale data.
- KEGG: Integrates genomic, chemical, and functional network data.
Applications in Various Fields
Medicine and Healthcare
One of bioinformatics’ most transformative applications is in medicine, particularly through projects like the Human Genome Project. This has facilitated:
- Personalized medicine: Tailoring treatments based on genetic profiles.
- Disease gene identification: Linking genetic variations to diseases.
- Drug discovery: Computational screening of drug candidates.
Agriculture and Environmental Science
Bioinformatics has also significantly impacted agriculture and environmental research by:
- Improving crop yields: Identifying genes linked to desirable traits.
- Combating plant diseases: Developing genetically resistant strains.
- Biodiversity conservation: Monitoring species at a genomic level.
Education and Training
With the growing significance of bioinformatics, educational initiatives have expanded, integrating:
- Online resources and databases: Facilitating global access to biological data.
- Training programs: Equipping researchers with computational skills.
- Interdisciplinary education: Merging biology, computer science, and mathematics.
Conclusion
Bioinformatics has evolved from a niche computational tool to a fundamental pillar of modern biological research. The field continues to expand, driven by technological advancements and the ever-growing need to analyze biological data efficiently. With its applications spanning medicine, agriculture, and environmental science, bioinformatics will remain at the forefront of scientific discovery, shaping the future of biological and biomedical research.
Related posts:
![CRISPR-COVID-19]()
CRISPR-Cas9 Mastery in Bioinformatics
bioinformatics![insurance-bioinformatics]()
Revolutionizing Insurance with Bioinformatics, Genomics, and Omics: A Comprehensive Guide
bioinformatics![biotech-bioinformatics-industry]()
Deep Learning in Bioinformatics and IoT Healthcare
A.I![blockchain in bioinformatics]()
Advanced Applications of Bioinformatics in Various Fields
bioinformatics![Y chromosome]()
Molecular Genetics: Principles and Applications
bioinformatics![variantcalling-bioinformatics]()
Is bioinformatics a good career?
bioinformatics![Docker-bioinformatics]()
Docker for Bioinformatics Analysis
bioinformatics![remotecomputer-bioinformatics]()
Step-By-Step Docker Installation on Windows and Linux
bioinformatics![computer-bioinformatics-chatgpt-claude]()
Cracking the Code of Life: How Computing Became the Game-Changer for Bioinformatics
bioinformatics![Computer-vaccine-design-bioinformatics]()
Step-by-Step Guide: How to Organize a Pipeline of Small Scripts Together in Bioinformatics
bioinformatics![Generative_AI]()
Generative AI for drug discovery
bioinformatics![Global Genomics Initiatives]()
Drug Repurposing: A Genomic Approach
A.I![Generative AI in Drug Discovery and Development]()
Unveiling Aging: Key Factors & Strategies through Bioinformatics
bioinformatics![android-app-bioinformatics]()
Basics of Android App Development for Bioinformatics
bioinformatics![Digital Health in Healthcare]()
Healthcare Foundation Models: Challenges, Opportunities, and Future Directions
A.I![bioinformatics-statistics]()
Find the Best Molecular Imaging Software for Your Research
bioinformatics

















