

Using GEO2R to Analyze Microarray Data
December 3, 2024Step-by-Step Tutorial: Using GEO2R to Analyze Microarray Data
GEO2R
Let’s look at differential expression of Mbp1 and its target genes using the analysis facilities of the GEO database at the NCBI.
Task…
First, we will search for relevant data sets on GEO, the NCBI’s database for expression data.
- Navigate to the entry page for ** GEO data sets].
- Enter the following query in the usual Entrez query format:
“cell cycle”[ti] AND “saccharomyces.
cerevisiae”[organism] - There are quite a few hits and it would take a while to sort through them. A study that has analyzed cell-cycle data in an interesting way is Pramila et al.’s Cell-Cycle study, a 13-samples analysis of wild-type yeast (W303a cells) across two cell-cycles after release from alpha-factor arrest.
- On the linked GEO DataSet Browser page, follow the link to the Accession Viewer page: the “Reference series”.
- Read about the experiment and samples, then follow the link to analyze with GEO2R
This tutorial will guide you through analyzing microarray data and retrieving a list of differentially expressed genes using GEO2R, based on the GEO Series GSE18388, which investigates gene expression changes in the thymus of mice subjected to spaceflight.
Step 1: Access the GEO Dataset
- Visit the GEO page for GSE18388.
- Scroll down and locate the “Analyze with GEO2R” link. Click on it to access the GEO2R tool.
Step 2: Review the Instructions and Limitations
- On the GEO2R page, find the “Full instructions” link at the top.
- This link explains the features and limitations of GEO2R, including statistical methods used and potential caveats.
Step 3: Define Groups
- Review the samples listed in the table. For this study:
- 4 samples are from space-flown mice.
- 4 samples are from ground control mice.
- Click “Define groups”.
- Enter group names (e.g., “space-flown” and “control”). Press Enter after each name.
- Assign samples to each group:
- Click a row and drag the cursor over the relevant samples.
- Assign them to the appropriate group.
Step 4: Check Data Distribution
- Navigate to the “Value distribution” tab and click “View”.
- A box plot will display the expression value distribution for each sample.
- Ensure the box plots are median-centered, indicating comparable distributions.
Step 5: Perform the Analysis
- Return to the GEO2R tab.
- Click “Top 250” to generate a table of the top 250 differentially expressed genes.
- The table is sorted by significance (P-values).
Step 6: View Gene Expression Profiles
- Click on a gene in the table (e.g., Rbm3, the top hit).
- View the expression profile chart:
- Red bars represent gene expression levels across samples.
- Group names are displayed at the bottom of the chart.
Step 7: Customize the Results Table
- Click “Select columns” to modify the table:
- Hide or expose columns like t-statistic, B-value, or Gene Ontology Function annotation.
- Click “Set” to update the table view.
Step 8: Save and Export Results
- To save the full set of results, click “Save all results”.
- This exports the data as a tab-delimited file.
Step 9: Adjust Test Settings (Optional)
- Navigate to the “Options” tab to modify test settings.
- Return to GEO2R and click “Re-calculate” to update the analysis.
Step 10: Use the R Script
- Go to the “R script” tab.
- The R script used for the analysis is provided.
- Save it for future reference.
Step 11: Investigate Specific Genes
- If you are interested in a specific gene:
- Find its identifier (ID) from the platform record linked on the GEO page.
- Enter the ID in the “Profile graph” tab and click “Set” to view the profile graph for that gene.
Step 12: Contact Support
If you have questions, use the GEO support email link at the top of the GEO2R page.
Conclusion
You have successfully analyzed microarray data using GEO2R, defined sample groups, checked data distribution, retrieved differentially expressed genes, and saved your results for further analysis.
Now proceed to apply what you have learned in the video-tutorial to the yeast cell-cycle study: 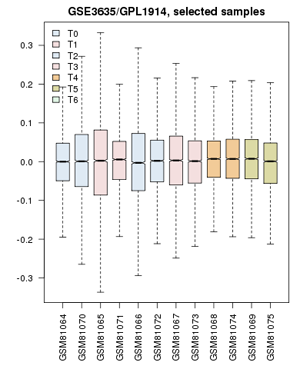
- Define groups: the associated publication shows us that one cell-cycle takes pretty exactly 60 minutes. Create timepoints T0, T1, T2, … T5. Then associate the 0 and 60 min. sample with “T0”; 10 and 70 minutes get grouped as “T1”; 20 and 80 minutes are T2, etc. up to T5. The final sample does not get assigned.
- Confirm that the Value distributions are unbiased by accessing the value distribution tab – overall, in such experiments, the bulk of the expression values should not change and thus means and quantiles of the expression levels should be about the same.
- Your distribution should look like the image on the right: properly grouped into six categories, and unbiased regarding absolute expression levels and trends.
- Look for differentially expressed genes: open the GEO2R tab and click on Top 250.
Analyze the results.
- Examine the top hits. Click on a few of the gene names in the Gene.symbol column to view the expression profiles that tell you why the genes were found to be differentially expressed. What do you think? Is this what you would have expected for genes’ responses to the cell-cycle? What seems to be the algorithm’s notion of what “differentially expressed” means?
- Look for expected genes. Here are a few genes that are known to be differentially expressed in the cell-cycle as target genes of the MBF complex:
DSE1,DSE2,ERF3,HTA2,HTB2, andGAS3. But what about the MBD complex proteins themselves: Mbp1 and Swi6?
The notion of “differential expression” and “cell-cycle dependent expression” do not overlap completely. Significant differential expression is mathematically determined for genes that have low variance within groups and large differences between groups. The algorithm has no concept of any expectation you might have about the shape of the expression profile. All it finds are genes for which differential expression between some groups is statistically supported. The algorithm returns the top 250 of those. Consistency within groups is very important, while we intuitively might be giving more weight to genes that conform to our expectations of a cyclical pattern.
Let’s see if we can group our time points differently to enhance the contrast between expression levels for cyclically expressed genes. Let’s define only two groups: one set before and between the two cycles, one set at the peaks – and we’ll omit some of the intermediate values.
- Remove all of your groups and define two groups only. Call them “A” and “B”.
- Assign samples for T = 0 min, 10, 60 and 70 min. to the “A” group. Assign sets 30, 40, 90, and 100 to the “B” group.
- Recalculate the Top 250 differentially expressed genes (you might have to refresh the page to get the “Top 250” button back.) Which of the “known” MBF targets are now contained in the set? What about Mbp1 and Swi6?
- Finally: Let’s compare the expression profiles for Mbp1, Swi6 and Swi4. It is not obvious that transcription factors are themselves under transcriptional control, as opposed to being expressed at a basal level and activated by phosporylation or ligand binding. In a new page, navigate to the Geo profiles page and enter
(Mbp1 OR Swi6 OR Swi4 OR Nrm1(Nrm1, Cln1, and Clb6 are Mbp1 target genes. Act1 and Alg9 are beta-Actin and mannosyltransferase, these are often considered to be “housekeeping genes, i.e. genes with unvarying expression levels, especially for qPCR studies – although Alg9 is also an Mbp1 target. We include them here as negative controls. CGSE3635 is the ID of the GEO data set we have just studied). You could have got similar results in the Profile graph tab of the GEO2R page. What do you find? What does this tell you? Would this information allow you to define groups that are even better suited for finding cyclically expressed genes?
OR Cln1 OR Clb6 OR Act1 OR Alg9) AND GSE3635 - Click on the profile graph for Mbp1. Describe the evidence you find on that page that allows us to conclude whether or not Mbp1 is a cell-cycle gene. You’ll probably want to think for a moment what this question really means, how a cell-cycle gene could be defined, and what can be considered “evidence”.
- Finally, note the R script for the GEO2R analysis in the R script tab. This code will run on your machine and make the expression analysis available. Once the datasets are loaded and prepared, you could – for example – perform a “real” time series analysis, calculate correlation coefficients with an idealized sine wave, or search for genes that are co-regulated with your genes of interest. We will explore this in another unit.
Related posts:
![AI and bioinformatics]()
Exploring the Impact of Personalized Medicine on Health Outcomes
bioinformatics![ChatGPT for Coders]()
Using ChatGPT in bioinformatics and biomedical research
bioinformatics![health informatics]()
Emerging areas of research and potential applications in bioinformatics
bioinformatics![AI in Genomics]()
How is AI applied in healthcare?
A.I![Visualization techniques for biological data]()
Introduction to Visualization Techniques for Biological Data in Bioinformatics
bioinformatics![CRISPR-COVID-19]()
Next-generation gene editing: CRISPR technology
bioinformatics![onlinecourse-bioinformatics.]()
Top 10 Must-Take Bioinformatics Courses for 2024 That Are Absolutely Free!
bioinformatics![bioinformatics-fileformat-basics]()
What Comes Next After a Bioinformatics Internship?
bioinformatics![Elephants Are Protected From Cancer by a Zombie Gene]()
Elephants Are Protected From Cancer by a Zombie Gene
bioinformatics![bioinformatics free online courses]()
Building Bioinformatics Tools with Python
bioinformatics![impact-of-Artificial-Intelligence-AI-on-academic-research]()
Digital Twins in Biology: Transforming Healthcare Through Virtual Modeling
bioinformatics![VR-in-healthcare]()
Bioinformatics in Medicine: Transforming Healthcare through Data Insights
bioinformatics![python-bioinformatics]()
Python via Bioinformatics Examples
bioinformatics![A Step-by-Step Guide to Molecular Dynamics (MD) Simulations Using Web-Based Tools: Case Study on AWS...]()
A Step-by-Step Guide to Molecular Dynamics (MD) Simulations Using Web-Based Tools: Case Study on AWS...
bioinformatics![python-bioinformatics-basics]()
Survival Analysis with Gene Expression in Bioinformatics: A Beginner's Guide
A.I![Visualization techniques for biological data]()
Biology Fundamentals for Bioinformatics
bioinformatics
















