

Introduction to Bioinformatics
March 6, 2024 Off By adminTable of Contents
ToggleWhat is Bioinformatics?
Bioinformatics is a multidisciplinary field that combines biology, computer science, mathematics, and statistics to analyze and interpret biological data, particularly at the molecular level. It involves the use of computational tools and techniques to study biological sequences, such as DNA, RNA, and proteins, as well as genome structure and function.
One of the primary goals of bioinformatics is to understand the structure, function, and evolution of biological macromolecules, such as proteins and nucleic acids. This is done through a variety of computational methods, including sequence alignment, structural modeling, and phylogenetic analysis.
Bioinformatics also plays a crucial role in genomics, the study of an organism’s entire genome. By analyzing genomic data, researchers can identify genes, predict gene functions, and study the evolution of gene families. Additionally, bioinformatics is used in transcriptomics, proteomics, and metabolomics to analyze gene expression, protein interactions, and metabolic pathways.
Overall, bioinformatics provides essential tools and insights for understanding the complex biological processes that govern life, and it is instrumental in advancing fields such as medicine, agriculture, and environmental science.
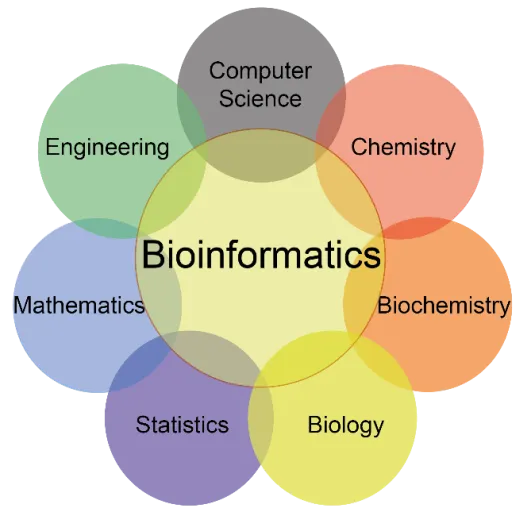
Bioinformatics or Biological analysis
Biological analysis extends traditional data analysis by integrating molecular information from various experimental platforms. It helps researchers understand how genes work together in molecular modules, their impact on higher-level biological processes and phenotypes, and their role in diseases.
For instance, in cancer research, biological analysis connects gene expression changes to observed cellular and disease phenotypes, revealing molecular mechanisms linking genotype to phenotype.
By identifying known relationships and providing a broader biological context, biological analysis enhances the interpretation of experimental results. It helps researchers understand key players, interactions, and pathways involved in their data set, facilitating a deeper understanding of the underlying biology.
Moreover, biological analysis can uncover key findings and novel discoveries from large datasets. For example, it can prioritize potential microRNA targets based on experimental evidence, tissue expression, and biomarker status, significantly reducing the time needed to make novel discoveries.
Furthermore, biological analysis speeds up hypothesis generation and validation. It helps researchers create hypotheses that are grounded in existing biological knowledge, increasing confidence in the experimental design and reducing the risk of pursuing dead-end research directions.
Overall, biological analysis accelerates the process of obtaining insights from experimental data, improves decision-making throughout the experimental cycle, and helps researchers avoid research obstacles and dead ends.

Why Bioinformatics?
Bioinformatics plays a crucial role in handling the vast amount of biological data being generated. In recent years, the amount of biological data stored in repositories such as GenBank, SwissProt, and the Protein Data Bank (PDB) has grown exponentially. GenBank, a comprehensive database of genetic sequences, now contains over 400 million sequences, with the latest count continuing to rise as more sequences are deposited. SwissProt, a curated protein sequence database, contains over 570,000 sequences, providing valuable information on protein functions, structures, and interactions. The Protein Data Bank (PDB), which stores 3D structural data of biological macromolecules, has surpassed 180,000 structures, revealing the intricate shapes and interactions that underlie biological processes. This exponential growth in data reflects the increasing pace of biological research and the importance of bioinformatics in organizing, analyzing, and interpreting these vast datasets to extract meaningful insights into the complexities of life.
Bioinformatics is a field that sits at the intersection of biology, computer science, and statistics. It emerged as a response to the vast amounts of biological data being generated, particularly from genome sequencing projects, and the need to organize, analyze, and interpret this data efficiently. Here are several reasons why bioinformatics is a crucial field:
- Big Data in Biology: With the advent of high-throughput technologies like next-generation sequencing and mass spectrometry, the volume of biological data being generated has exploded. Bioinformatics provides the tools and methods necessary to make sense of this data and extract meaningful insights.
- Understanding Biological Systems: Bioinformatics helps us understand the complexity of biological systems at a molecular level. By analyzing genomic, transcriptomic, proteomic, and metabolomic data, researchers can gain insights into how genes, proteins, and other molecules interact to regulate biological processes.
- Disease Research and Drug Discovery: Bioinformatics plays a crucial role in disease research and drug discovery. By analyzing genomic and clinical data, researchers can identify genetic variations associated with diseases, predict drug responses, and develop personalized treatment strategies.
- Precision Medicine: Bioinformatics is essential for the advancement of precision medicine, which aims to tailor medical treatment to the individual characteristics of each patient. By analyzing genomic and other omics data, researchers can identify biomarkers for disease diagnosis, prognosis, and treatment selection.
- Evolutionary Biology: Bioinformatics is instrumental in studying the evolution of species by comparing their genomes. By analyzing sequence data, researchers can reconstruct evolutionary relationships, identify genes under selection, and understand the genetic basis of adaptation.
- Biotechnology and Synthetic Biology: Bioinformatics is crucial for biotechnological applications, such as the design of enzymes for industrial processes, the development of genetically modified organisms, and the engineering of synthetic biological systems.
- Environmental and Agricultural Applications: Bioinformatics is used in environmental studies to analyze microbial communities and their functions in various ecosystems. In agriculture, bioinformatics helps in crop improvement by identifying genes associated with desirable traits.
- Public Health and Epidemiology: Bioinformatics is vital for monitoring and controlling infectious diseases. By analyzing genomic data from pathogens, researchers can track disease outbreaks, identify drug-resistant strains, and develop targeted intervention strategies.
In conclusion, bioinformatics is a rapidly evolving field with a wide range of applications in biological research, medicine, biotechnology, and beyond. Its interdisciplinary nature makes it a fascinating and rewarding field for those interested in using data science to tackle complex biological problems.
In the era of big data in bioinformatics, researchers face the challenge of efficiently analyzing massive amounts of data generated from various biological experiments. To address this challenge, in silico methods have become essential. In silico, which means “performed on computer or via computer simulation,” allows researchers to analyze data quickly and efficiently using computational tools and algorithms.
The sheer volume of data generated from experiments such as high-throughput sequencing, mass spectrometry, and microarray experiments is too vast to be manually analyzed. In silico methods enable researchers to process and analyze this data rapidly, allowing for the extraction of valuable insights and patterns that would be difficult or impossible to detect using traditional manual methods.
One of the key advantages of in silico analysis is the ability to make use of all available information. By leveraging computational algorithms, researchers can integrate data from multiple sources and types, such as genomic, transcriptomic, proteomic, and metabolomic data, to gain a comprehensive understanding of biological systems.
Organizing and managing such large volumes of data using traditional methods, such as lab notebooks, is impractical. In silico methods provide a more efficient and organized way to store, access, and analyze data, ensuring that valuable information is not overlooked or lost.
Automation is a key feature of in silico analysis. By automating repetitive tasks and data processing steps, researchers can save time and resources, allowing them to focus on more complex analysis and interpretation tasks. Automation also reduces the risk of human error, ensuring the accuracy and reliability of the results.
While in silico analysis offers many benefits, it is important to note that all results should be verified by biologists. While computational methods can provide valuable insights and hypotheses, experimental validation is essential to confirm the findings and ensure their relevance to biological systems. Collaborations between bioinformaticians and biologists are crucial for interpreting and applying in silico results effectively in biological research.
Aims of bioinformatics
The aims of bioinformatics encompass a wide range of goals, all aimed at leveraging computational tools and techniques to advance biological research. Here are some key aims:
- Data Organization: One of the primary aims of bioinformatics is to organize biological data in a way that allows researchers to access existing information easily and submit new entries as they are produced. This includes developing databases and data storage systems that can efficiently handle the vast amounts of data generated by modern biological research.
- Tool Development: Bioinformatics aims to develop tools and resources for the analysis of biological data. This includes software tools for sequence alignment, protein structure prediction, and phylogenetic analysis, among others. These tools help researchers compare new protein sequences with previously characterized sequences and extract meaningful information from large datasets.
- Data Analysis: Bioinformatics aims to use these tools to analyze biological data and interpret the results in a biologically meaningful manner. This includes identifying patterns in genomic, transcriptomic, proteomic, and metabolomic data, as well as predicting the structure and function of biological molecules.
- Integration of Data: Another aim of bioinformatics is to integrate data from multiple sources and types to gain a more comprehensive understanding of biological systems. This includes integrating genomic, transcriptomic, proteomic, and metabolomic data to study how genes, proteins, and other molecules interact to regulate biological processes.
- Predictive Modeling: Bioinformatics aims to develop predictive models of biological systems. This includes predicting the structure and function of proteins based on their amino acid sequences, as well as predicting the effects of genetic variations on phenotype.
- Biological Interpretation: Ultimately, the goal of bioinformatics is to translate raw data into biologically meaningful insights. This includes identifying potential drug targets, understanding the genetic basis of disease, and predicting how genetic variations impact human health.
Overall, bioinformatics aims to leverage computational tools and techniques to advance our understanding of biological systems and ultimately improve human health and well-being.
Importance of Bioinformatics
Bioinformatics plays a crucial role in modern biological research and has become increasingly important due to the explosion of biological data generated by high-throughput technologies. Several key concepts and foundations underpin the importance of bioinformatics:
- Data Representation: Bioinformatics is essential for representing biological data in a format that can be easily analyzed and interpreted. This includes representing DNA sequences, protein structures, and other biological data in a digital format that can be processed by computers.
- Concept of Similarity: Bioinformatics relies heavily on the concept of similarity to compare biological sequences and structures. By identifying similarities between different sequences or structures, researchers can infer evolutionary relationships, predict protein function, and identify potential drug targets.
- Information Stored in Databases: One of the foundational aspects of bioinformatics is the vast amount of information stored in various databases. These databases contain genomic sequences, protein structures, gene expression data, and other biological information that is essential for conducting research in bioinformatics.
Overall, bioinformatics is crucial for organizing, analyzing, and interpreting biological data, and it has become an indispensable tool for researchers in the life sciences.
Bioinformatics plays a crucial role in advancing biological research and has several important aspects:
- Data Management: Bioinformatics helps in managing and organizing vast amounts of biological data, such as DNA sequences, protein structures, and gene expression profiles. It enables researchers to store, retrieve, and analyze data efficiently.
- Sequence Analysis: One of the fundamental tasks in bioinformatics is analyzing DNA, RNA, and protein sequences. This analysis helps in understanding genetic variations, evolutionary relationships, and functional elements in genomes.
- Structural Biology: Bioinformatics tools are used to predict and analyze the three-dimensional structures of proteins and nucleic acids. This information is essential for understanding their functions and interactions with other molecules.
- Functional Genomics: Bioinformatics helps in annotating genes and predicting their functions based on sequence and structural information. This is crucial for understanding the roles of genes in various biological processes.
- Comparative Genomics: By comparing genomes of different organisms, bioinformatics can reveal evolutionary relationships, identify conserved regions, and discover genes unique to particular species.
- Systems Biology: Bioinformatics plays a key role in systems biology, which aims to understand complex biological systems as a whole. It involves integrating data from multiple sources to model and simulate biological processes.
- Drug Discovery and Development: Bioinformatics is used in drug discovery to identify potential drug targets, predict drug interactions, and optimize drug candidates. It speeds up the process of drug development and reduces costs.
- Personalized Medicine: By analyzing individual genetic variations, bioinformatics contributes to personalized medicine, where treatments are tailored to individual patients based on their genetic makeup.
- Biomedical Research: Bioinformatics is used in various areas of biomedical research, including cancer genomics, infectious disease modeling, and understanding the genetic basis of diseases.
Overall, bioinformatics is essential for advancing our understanding of biology, improving healthcare, and developing new technologies and therapies.
Data representation
Data representation is a fundamental concept in bioinformatics, particularly in the context of DNA sequences. The complex, dynamic, three-dimensional DNA molecule is represented as a simple string of characters: A, C, G, and T, which represent the four nucleotides adenine, cytosine, guanine, and thymine, respectively. This representation allows researchers to store and analyze DNA sequences using computational tools and algorithms.
The simplicity of this representation belies the complexity of the underlying biological molecule. DNA sequences can be millions or even billions of nucleotides long, encoding the genetic information that determines an organism’s traits and functions. By representing DNA sequences as strings of characters, bioinformaticians can perform a wide range of analyses, including sequence alignment, gene prediction, and phylogenetic analysis, to gain insights into the structure, function, and evolution of genes and genomes.
In addition to DNA sequences, other biological data, such as protein sequences, gene expression levels, and protein structures, are also represented in a digital format using specific conventions and standards. This standardized representation of biological data enables researchers to share, compare, and analyze data across different studies and research groups, advancing our understanding of the complexities of living organisms.
In addition to DNA sequences, proteins are another key focus of bioinformatics, and their representation is equally important. Proteins are complex molecules composed of amino acids, and their primary structure, which is the linear sequence of amino acids, is represented using a similar approach as DNA sequences.
In protein sequences, each amino acid is represented by a single-letter code, such as ‘A’ for alanine, ‘R’ for arginine, and so on. This one-letter code simplifies the representation of protein sequences, allowing for easy storage and analysis using computational tools.
Protein structures, on the other hand, are three-dimensional arrangements of amino acids that fold into specific shapes, known as the protein’s tertiary structure. Protein structures are typically represented using coordinate data that describe the position of each atom in the protein. This representation allows researchers to visualize and analyze the structure of proteins, which is crucial for understanding their function and interactions with other molecules.
Overall, the representation of biological data, including DNA sequences and protein structures, in a digital format is essential for bioinformatics. It enables researchers to store, analyze, and interpret biological information using computational tools, leading to new insights into the structure, function, and evolution of biological molecules.
In bioinformatics, data representation is crucial for storing, organizing, and analyzing biological data. Here are some common types of data representation used in bioinformatics:
- Sequence Data: Sequences of DNA, RNA, and proteins are represented using letters from the respective alphabets (A, T, G, C for DNA; A, U, G, C for RNA; and 20 amino acid codes for proteins). Sequences can be represented as strings or in formats like FASTA and GenBank.
- Structural Data: Data related to the three-dimensional structures of molecules, such as proteins and nucleic acids, are represented using coordinate files (e.g., PDB format for protein structures). Structural data can also include annotations about atoms, bonds, and secondary structures.
- Genomic Data: Genomic data, such as gene annotations, single nucleotide polymorphisms (SNPs), and chromosomal locations, are represented in formats like BED, GFF, or VCF. These formats provide information about the genomic features and variations.
- Expression Data: Data related to gene expression levels, such as microarray or RNA-seq data, are represented as matrices, where rows correspond to genes and columns correspond to samples. Each entry in the matrix represents the expression level of a gene in a sample.
- Network Data: Biological networks, such as protein-protein interaction networks or metabolic pathways, are represented using graph structures. Nodes represent biological entities (e.g., proteins, metabolites), and edges represent relationships or interactions between them.
- Phylogenetic Data: Phylogenetic trees, representing evolutionary relationships between species or genes, are represented as hierarchical structures. Trees can be represented in Newick or Nexus formats.
- Metadata: Additional information about biological samples, experiments, or datasets is represented as metadata. Metadata can include details like sample identifiers, experimental conditions, and data processing steps.
- Images and Visualizations: Bioinformatics often involves visualizing complex biological data. Images and visualizations are used to represent sequence alignments, protein structures, and other biological features.
Effective data representation in bioinformatics facilitates data sharing, collaboration, and analysis, enabling researchers to gain insights into biological systems and processes.
Concept of similarity
The concept of similarity is central to bioinformatics, especially in the context of comparing biological sequences such as DNA, RNA, and proteins. Several key principles underpin this concept:
- Evolutionary Conservation: Evolution tends to conserve genes that encode important proteins and sequences involved in gene regulation. This conservation leads to similarities between sequences in different species that share a common ancestor. By comparing sequences, researchers can infer evolutionary relationships and identify conserved regions that are likely to be functionally important.
- Horizontal Gene Transfer: Sequences that encode useful functions can be transferred from one organism to another through processes such as horizontal gene transfer. This transfer can result in similar sequences being present in distantly related species. By studying similarities between sequences, researchers can uncover the history of gene transfer events and gain insights into the evolution of biological functions.
- Functional Similarity: Similar sequences often have similar functions. This principle is based on the idea that the structure and function of a protein are determined by its amino acid sequence. Therefore, sequences that are similar at the amino acid level are likely to have similar functions. By comparing protein sequences, researchers can predict the function of uncharacterized proteins based on their similarity to known proteins.
Overall, the concept of similarity is crucial for understanding the relationships between biological sequences and predicting the function of genes and proteins. By studying similarities, researchers can uncover evolutionary relationships, identify functional domains, and gain insights into the underlying biology of living organisms.
In bioinformatics, the concept of similarity refers to the degree of resemblance or correspondence between biological sequences, structures, or other entities. Similarity is a fundamental concept used in various analyses and comparisons, such as sequence alignment, phylogenetic analysis, and functional annotation. Here are some key aspects of similarity in bioinformatics:
- Sequence Similarity: In sequence analysis, similarity refers to the degree of identity or similarity between two or more sequences of DNA, RNA, or proteins. Sequence similarity is often measured using metrics such as percent identity or similarity scores from alignment algorithms like BLAST.
- Structural Similarity: For proteins and nucleic acids, structural similarity refers to the degree of resemblance in their three-dimensional structures. Structural similarity can reveal evolutionary relationships, functional similarities, and potential drug binding sites.
- Functional Similarity: Functional similarity relates to the similarity in biological function or activity between genes, proteins, or other molecules. Functional similarity can be inferred based on sequence or structural similarities, as well as experimental data.
- Homology: Homology is a special case of similarity where two or more sequences share a common evolutionary origin. Homologous sequences are related by descent from a common ancestor and may retain similar functions.
- Analogous Structures: Analogous structures are structures that have similar functions but different evolutionary origins. They may exhibit superficial similarities but do not share a common evolutionary history.
- Similarity Searching: Bioinformatics tools like BLAST and FASTA are used to search for similar sequences in databases. These tools use algorithms to find sequences that are most similar to a query sequence.
- Sequence Alignment: Sequence alignment is a process of arranging sequences to identify regions of similarity that may indicate functional, structural, or evolutionary relationships. Alignment algorithms aim to maximize the similarity between aligned residues.
- Scoring Matrices: Scoring matrices, such as BLOSUM and PAM matrices, are used in sequence alignment to quantify the similarity between amino acids or nucleotides based on their observed frequencies in biological sequences.
Understanding similarity in bioinformatics is essential for inferring biological function, evolutionary relationships, and structure-function correlations. It enables researchers to compare and analyze biological data to gain insights into the underlying biology.
Foundation of Bioinformatics
The foundation of bioinformatics lies in the vast amount of information stored in various databases, which serve as repositories for biological data. These databases contain genomic sequences, protein structures, gene expression data, and other types of biological information that are essential for conducting research in bioinformatics. Several key points highlight the importance of these databases:
- Data-Driven Science: Bioinformatics is inherently a data-driven science. It is driven by the data generated from biological experiments, which is then analyzed and interpreted using computational tools and algorithms. The availability of large datasets in these databases enables researchers to conduct analyses that would not be possible with smaller datasets.
- Real-World Application: The data stored in these databases are not just theoretical constructs but are derived from real-world biological systems. This data reflects the complexity and diversity of living organisms and serves as the foundation for understanding biological processes at a molecular level.
- Algorithm Development: While bioinformatics is driven by data, researchers also have the opportunity to develop algorithms and theories to analyze and interpret this data. The development of these algorithms is often motivated by the need to address specific challenges or questions posed by the data stored in these databases.
- Integration of Data: One of the key strengths of bioinformatics is its ability to integrate data from multiple sources and types. The data stored in these databases serve as the building blocks for constructing integrated models of biological systems, enabling researchers to gain a more comprehensive understanding of complex biological processes.
In conclusion, the information stored in various databases is the foundation of bioinformatics. It provides researchers with the raw material needed to conduct analyses, develop algorithms, and generate new insights into the structure, function, and evolution of biological systems.
The foundation of bioinformatics databases lies in the need to organize and store biological data in a structured and accessible manner. These databases serve as repositories for various types of biological data, such as DNA sequences, protein sequences, gene expression data, and structural information. Here are some key aspects of the foundation of bioinformatics databases:
- Data Organization: Bioinformatics databases are designed to organize biological data according to specific data types and formats. For example, sequence databases organize DNA and protein sequences, while structural databases organize information about protein structures.
- Data Integration: Many bioinformatics databases aim to integrate data from multiple sources to provide a comprehensive view of biological systems. This integration allows researchers to access and analyze data from different sources in a unified manner.
- Data Retrieval: Bioinformatics databases provide tools and interfaces for researchers to retrieve data based on specific criteria, such as sequence similarity, keyword searches, or metadata filters. This enables efficient access to relevant data for analysis.
- Data Annotation: Databases often include annotation information for biological data, such as gene names, protein functions, and sequence features. This annotation helps researchers interpret and analyze the data more effectively.
- Data Sharing: Bioinformatics databases facilitate data sharing among researchers and institutions by providing public access to data. This promotes collaboration and accelerates research progress by allowing researchers to build on existing data.
- Data Security: Since biological data is sensitive and valuable, bioinformatics databases implement security measures to protect data integrity and privacy. This includes access control, encryption, and data backup mechanisms.
- Data Standards: Bioinformatics databases adhere to data standards and formats to ensure interoperability and compatibility with other databases and tools. Standards such as FASTA, GenBank, and PDB are commonly used in bioinformatics databases.
- Data Curation: Databases often involve manual curation of data to ensure accuracy, consistency, and completeness. Curators review and update data regularly to maintain its quality and relevance.
Overall, the foundation of bioinformatics databases is built on principles of data organization, integration, retrieval, annotation, sharing, security, standards, and curation. These databases play a crucial role in advancing biological research by providing a centralized and structured repository of biological data for analysis and interpretation.
The foundation of bioinformatics lies at the intersection of biology, computer science, mathematics, and statistics. It is built upon several key principles and concepts:
- Molecular Biology: Bioinformatics is rooted in molecular biology, which studies the structure, function, and interactions of biological molecules, such as DNA, RNA, and proteins. Understanding these molecules is essential for interpreting biological data.
- Genomics: Genomics is the study of genomes, including their structure, function, evolution, and mapping. Bioinformatics plays a crucial role in analyzing and interpreting genomic data, such as DNA sequences.
- Proteomics: Proteomics is the study of proteins, including their structure, function, and interactions. Bioinformatics tools are used to analyze protein sequences, predict their structures, and identify protein-protein interactions.
- Computational Biology: Computational biology is the application of computational techniques to analyze and model biological systems. Bioinformatics uses computational methods to process, analyze, and interpret biological data.
- Mathematics and Statistics: Bioinformatics relies heavily on mathematical and statistical methods for data analysis, hypothesis testing, and modeling. These disciplines provide the foundation for understanding and interpreting biological data.
- Data Management: Bioinformatics involves the management and analysis of large volumes of biological data, such as DNA sequences, gene expression profiles, and protein structures. Effective data management is essential for organizing and processing this data.
- Sequence Alignment: Sequence alignment is a fundamental concept in bioinformatics, which involves comparing and aligning biological sequences to identify similarities and differences. This process is essential for understanding evolutionary relationships and predicting protein structures.
- Database Management: Bioinformatics databases store a vast amount of biological data, such as genome sequences, protein structures, and gene expression profiles. Database management is critical for organizing and accessing this data efficiently.
- Algorithm Development: Bioinformatics develops algorithms and computational tools for analyzing biological data, such as sequence alignment algorithms, phylogenetic tree construction methods, and protein structure prediction algorithms.
- Interdisciplinary Collaboration: Bioinformatics requires collaboration between biologists, computer scientists, mathematicians, and statisticians to address complex biological problems. This interdisciplinary approach is essential for advancing the field.
Overall, the foundation of bioinformatics lies in its multidisciplinary nature, combining principles and concepts from biology, computer science, mathematics, and statistics to analyze and interpret biological data.
Application of bioinformatics
DNA sequence analysis
Bioinformatics plays a crucial role in the analysis of DNA sequences, providing tools and techniques to extract valuable information from DNA data. Some key applications of bioinformatics in DNA sequence analysis include:
- Sequence Alignment: Bioinformatics tools like BLAST (Basic Local Alignment Search Tool) are used to align DNA sequences with each other or with known reference sequences. This helps in identifying similarities, differences, and evolutionary relationships between sequences.
- Genome Assembly: Bioinformatics algorithms are used to assemble short DNA sequencing reads into longer contiguous sequences (contigs) or complete genomes. This process is essential for studying the structure and function of genomes.
- Gene Prediction: Bioinformatics tools can predict the location and structure of genes within DNA sequences. This is done by identifying characteristic features such as start codons, stop codons, and splice sites.
- Functional Annotation: Bioinformatics is used to annotate DNA sequences with functional information, such as the predicted functions of genes and regulatory elements. This helps in understanding the biological significance of DNA sequences.
- Comparative Genomics: Bioinformatics enables the comparison of DNA sequences from different organisms to identify similarities, differences, and evolutionary relationships. This helps in studying the evolution of species and the function of genes.
- Variant Analysis: Bioinformatics tools are used to identify and analyze genetic variants, such as single nucleotide polymorphisms (SNPs) and insertions/deletions (indels), in DNA sequences. This is important for studying genetic diversity and disease associations.
- Metagenomics: Bioinformatics is used in metagenomics to analyze DNA sequences from environmental samples, such as soil or water, to study microbial communities and their functions.
- Phylogenetic Analysis: Bioinformatics tools are used to construct phylogenetic trees based on DNA sequences to study the evolutionary relationships between species or genes.
- Epigenetics: Bioinformatics is used to analyze DNA methylation patterns and histone modifications, which are important for regulating gene expression and chromatin structure.
Overall, bioinformatics plays a critical role in DNA sequence analysis, enabling researchers to extract valuable information from DNA data and understand the structure, function, and evolution of genomes.
Sequence annotation and Genomics
Sequence annotation is the process of identifying and assigning functional information to the features of a DNA, RNA, or protein sequence. In genomics, sequence annotation plays a crucial role in understanding the structure and function of genomes. Here are key aspects of sequence annotation in genomics:
- Gene Prediction: One of the primary goals of sequence annotation is to identify genes within a genome. Gene prediction algorithms use various features such as open reading frames (ORFs), splice sites, and start/stop codons to predict the locations and structures of genes.
- Functional Annotation: Once genes are identified, their functions need to be annotated. This involves predicting the functions of proteins encoded by the genes based on similarity to known proteins, domain analysis, and functional motifs.
- Non-coding RNA Annotation: In addition to protein-coding genes, genomes also contain non-coding RNA genes, such as transfer RNA (tRNA), ribosomal RNA (rRNA), and microRNA (miRNA). Sequence annotation includes identifying and annotating these non-coding RNA genes.
- Promoter and Regulatory Element Annotation: Annotating regulatory elements, such as promoters, enhancers, and transcription factor binding sites, helps in understanding gene regulation and expression patterns.
- Repeat and Transposable Element Annotation: Genomes often contain repetitive sequences and transposable elements. Annotating these elements is important for understanding genome structure, evolution, and gene regulation.
- Structural Annotation: In addition to functional annotation, sequence annotation also includes predicting the secondary and tertiary structures of proteins encoded by genes. This helps in understanding protein function and interactions.
- Comparative Genomics: Comparative genomics involves comparing the annotated features of one genome with those of other related genomes. This comparative analysis can provide insights into genome evolution, gene function, and species diversity.
- Database Annotation: Annotated sequences are stored in databases, such as GenBank, RefSeq, and Ensembl, where they can be accessed and analyzed by researchers worldwide. These databases play a crucial role in genomics research and data sharing.
Sequence annotation in genomics is a complex and ongoing process that requires the integration of computational tools, experimental data, and biological knowledge. It is essential for understanding the structure, function, and evolution of genomes and is a key step in genomic research.
Evolutionary studies and Phylogenetics
Evolutionary studies and phylogenetics are fields of biology that use DNA and protein sequence data to study the evolutionary relationships between organisms. Here’s how bioinformatics plays a crucial role in these areas:
- Sequence Alignment: Bioinformatics tools are used to align DNA or protein sequences from different species to identify similarities and differences. This information is used to infer evolutionary relationships and construct phylogenetic trees.
- Phylogenetic Tree Construction: Phylogenetic trees are diagrams that show the evolutionary relationships between organisms. Bioinformatics algorithms, such as maximum likelihood and Bayesian methods, are used to construct these trees based on sequence data.
- Molecular Clock Analysis: Bioinformatics is used to analyze sequence data to estimate the rate at which mutations accumulate over time. This molecular clock can be used to estimate the timing of evolutionary events and divergence between species.
- Homology and Orthology Analysis: Bioinformatics tools are used to identify homologous genes (genes that share a common ancestor) and orthologous genes (genes that diverged through speciation). This information is used to infer evolutionary relationships and study gene function.
- Phylogenetic Profiling: Bioinformatics tools are used to analyze the presence or absence of genes across different species. This information can be used to infer the evolutionary history of genes and gene families.
- Comparative Genomics: Bioinformatics is used to compare the genomes of different species to study genome evolution, gene duplication, and gene loss. This comparative analysis provides insights into the genetic basis of evolutionary change.
- Population Genetics: Bioinformatics is used to analyze genetic variation within and between populations. This information is used to study population dynamics, genetic diversity, and adaptation to different environments.
- Evolutionary Genomics: Bioinformatics is used to study the evolution of entire genomes, including gene order, genome structure, and regulatory elements. This provides insights into the mechanisms driving genome evolution.
Overall, bioinformatics plays a critical role in evolutionary studies and phylogenetics by providing tools and methods to analyze and interpret DNA and protein sequence data, helping researchers understand the evolutionary history of life on Earth.
Development of algorithms and tools
Development of algorithms and tools in bioinformatics is crucial for analyzing and interpreting biological data. Here are some key aspects of algorithm and tool development in bioinformatics:
- Sequence Alignment: Algorithms for pairwise and multiple sequence alignment are essential for comparing DNA, RNA, and protein sequences. Tools like BLAST, ClustalW, and MAFFT are commonly used for sequence alignment.
- Phylogenetic Analysis: Algorithms for constructing phylogenetic trees from sequence data are important for studying evolutionary relationships. Maximum likelihood, Bayesian inference, and neighbor-joining algorithms are used for phylogenetic analysis.
- Gene Prediction: Algorithms for predicting genes in DNA sequences are essential for identifying coding regions and non-coding regions. Tools like GeneMark, Augustus, and Glimmer are used for gene prediction.
- Structural Bioinformatics: Algorithms for predicting protein structures and analyzing protein-ligand interactions are important for understanding protein function. Tools like SWISS-MODEL, PyMOL, and AutoDock are used for structural bioinformatics.
- Functional Annotation: Algorithms for annotating biological sequences with functional information are important for interpreting sequence data. Tools like InterProScan, DAVID, and GO-Elite are used for functional annotation.
- Next-Generation Sequencing (NGS) Analysis: Algorithms for analyzing NGS data, including read alignment, variant calling, and de novo assembly, are essential for studying genomes and transcriptomes. Tools like BWA, GATK, and Trinity are used for NGS analysis.
- Network Analysis: Algorithms for analyzing biological networks, such as protein-protein interaction networks and metabolic networks, are important for understanding complex biological systems. Tools like Cytoscape, STRING, and MetScape are used for network analysis.
- Machine Learning and Data Mining: Algorithms for machine learning and data mining are increasingly being used in bioinformatics for tasks such as pattern recognition, classification, and prediction. Tools like WEKA, scikit-learn, and TensorFlow are used for machine learning in bioinformatics.
Overall, the development of algorithms and tools in bioinformatics is essential for advancing our understanding of biological systems and interpreting complex biological data. These algorithms and tools enable researchers to analyze large-scale biological datasets and uncover new insights into the structure, function, and evolution of biological systems.
Measuring Biodiversity
Measuring biodiversity involves quantifying the variety and variability of living organisms in a given area or ecosystem. Bioinformatics plays a crucial role in biodiversity assessment by providing tools and methods for analyzing genetic, species, and ecosystem diversity. Here are some key aspects of measuring biodiversity using bioinformatics:
- DNA Barcoding: DNA barcoding involves sequencing a short standardized region of DNA to identify and classify species. Bioinformatics tools are used to analyze and compare DNA barcode sequences to assess species diversity and identify unknown species.
- Metagenomics: Metagenomics involves studying the genetic material recovered directly from environmental samples. Bioinformatics tools are used to analyze metagenomic data to assess microbial diversity, identify new species, and study microbial communities.
- Phylogenetic Analysis: Phylogenetic analysis involves constructing evolutionary trees to understand the relationships between species. Bioinformatics tools are used to analyze DNA or protein sequences to infer phylogenetic relationships and assess species diversity.
- Species Distribution Modeling: Species distribution modeling uses environmental data and species occurrence records to predict the geographic distribution of species. Bioinformatics tools are used to analyze and model species distributions based on ecological niches and environmental factors.
- Functional Diversity Analysis: Functional diversity analysis involves assessing the variety of ecological functions performed by different species in an ecosystem. Bioinformatics tools are used to analyze functional traits and assess functional diversity within and between species.
- Community Structure Analysis: Community structure analysis involves studying the composition and interactions of species within an ecosystem. Bioinformatics tools are used to analyze species abundance data and assess community structure, including species richness and evenness.
- Ecological Network Analysis: Ecological network analysis involves studying the complex interactions between species in an ecosystem. Bioinformatics tools are used to analyze ecological networks, including food webs, mutualistic networks, and interaction networks.
Overall, bioinformatics provides powerful tools and methods for measuring biodiversity, allowing researchers to assess the variety and variability of life forms in different ecosystems and understand the complex patterns and processes that contribute to biodiversity.
Structure prediction
Structure prediction in bioinformatics refers to the process of predicting the three-dimensional structure of biological macromolecules, such as proteins, RNA, and DNA, based on their amino acid or nucleotide sequences. Here are key aspects of structure prediction:
- Protein Structure Prediction: Protein structure prediction is a fundamental problem in bioinformatics due to the importance of protein structure in determining function. There are two main approaches to protein structure prediction:
- Homology Modeling (Comparative Modeling): This method predicts the structure of a target protein based on the known structure of a homologous protein (template). It relies on the assumption that proteins with similar sequences have similar structures.
- Ab Initio (De Novo) Modeling: This method predicts protein structure from scratch, without using known homologous structures. It relies on physical principles and statistical potentials to predict the most energetically favorable protein conformation.
- RNA Structure Prediction: RNA structure prediction aims to predict the secondary and tertiary structures of RNA molecules, which are crucial for their function in gene regulation and protein synthesis. Similar to protein structure prediction, RNA structure prediction can be done using comparative modeling or ab initio modeling approaches.
- DNA Structure Prediction: DNA structure prediction focuses on predicting the three-dimensional structure of DNA molecules, including the formation of DNA-protein complexes (e.g., transcription factors binding to DNA). This helps in understanding the regulation of gene expression and DNA repair mechanisms.
- Molecular Docking: Molecular docking predicts the three-dimensional structure of protein-ligand complexes, which is important for drug discovery and design. It involves predicting the binding pose and affinity of a ligand to a target protein.
- Structure Validation: Once a structure is predicted, it needs to be validated to ensure its quality and reliability. Validation methods include assessing stereochemical quality, structural completeness, and agreement with experimental data (if available).
- Bioinformatics Tools: Various bioinformatics tools and software packages are available for structure prediction, such as MODELLER, SWISS-MODEL, Rosetta, and RNAstructure, which implement different algorithms and approaches for predicting biological macromolecule structures.
Structure prediction in bioinformatics is a complex and challenging problem, but advancements in computational methods and algorithms have greatly improved our ability to predict accurate structures, leading to a better understanding of biological processes and the development of new therapeutics.
Cheminformatics and drug design
Cheminformatics, also known as chemoinformatics, is the application of informatics techniques to solve chemical problems. It involves the use of computational methods and tools to analyze, visualize, and predict chemical data, particularly in the context of drug discovery and design. Here’s how cheminformatics is used in drug design:
- Chemical Database Management: Cheminformatics involves the management of chemical databases containing information about chemical structures, properties, and activities. These databases are essential for storing and retrieving chemical information for drug discovery.
- Virtual Screening: Cheminformatics tools are used for virtual screening of large chemical libraries to identify potential drug candidates. Virtual screening involves docking small molecules into the active sites of target proteins to predict their binding affinity and selectivity.
- QSAR/QSPR Modeling: Quantitative Structure-Activity Relationship (QSAR) and Quantitative Structure-Property Relationship (QSPR) models are used in cheminformatics to predict the biological activity or physicochemical properties of chemical compounds based on their chemical structures. These models are used to prioritize compounds for further testing.
- Chemical Similarity Analysis: Cheminformatics tools are used to analyze chemical similarity between compounds. Similarity analysis helps in identifying structurally similar compounds with similar biological activities, which can be used as lead compounds for drug design.
- ADME/Tox Prediction: Absorption, Distribution, Metabolism, Excretion (ADME) and Toxicity (Tox) prediction models are used in cheminformatics to predict the pharmacokinetic and toxicological properties of chemical compounds. These models help in identifying compounds with desirable ADME/Tox profiles for drug development.
- Fragment-Based Drug Design: Cheminformatics tools are used in fragment-based drug design, where small molecular fragments are used as building blocks to design and optimize drug candidates. Fragment-based approaches rely on computational methods to predict the binding affinity and selectivity of fragment hits.
- Structure-Based Design: Cheminformatics is used in structure-based drug design, where the three-dimensional structure of a target protein is used to design ligands that bind to the target with high affinity and selectivity. Computational methods are used to predict the binding mode and affinity of designed ligands.
- Chemical Visualization and Analysis: Cheminformatics tools are used to visualize and analyze chemical structures, properties, and activities. Visualization tools help in understanding the structure-activity relationships (SAR) and optimizing chemical structures for improved biological activity.
Cheminformatics plays a critical role in modern drug discovery and design by providing computational tools and methods to analyze and interpret chemical data, leading to the discovery of novel drug candidates with improved efficacy and safety profiles.
Future prospects in drug modification
In the field of drug modification, there are several exciting future prospects and trends that hold promise for advancing drug design and development. Some of these prospects include:
- Precision Medicine: Precision medicine aims to tailor medical treatment to the individual characteristics of each patient, including their genetic makeup, lifestyle, and environment. Drug modification strategies that target specific molecular pathways or genetic mutations associated with diseases can lead to more personalized and effective treatments.
- Targeted Therapies: Targeted therapies focus on specific molecular targets involved in disease pathways, such as proteins or genes. Drug modification techniques, such as structure-based drug design and molecular modeling, can help design drugs that selectively target these specific targets, leading to more effective and less toxic treatments.
- Biologics and Gene Therapies: Advances in biotechnology have led to the development of biologics, such as monoclonal antibodies and gene therapies, which offer new avenues for drug modification. These therapies can target specific disease-causing molecules or genes, providing highly targeted and effective treatments.
- Drug Repurposing: Drug repurposing, or repositioning, involves finding new uses for existing drugs. Computational methods in cheminformatics can help identify new therapeutic indications for existing drugs by analyzing their chemical structures and biological activities, leading to the development of new treatments for various diseases.
- Artificial Intelligence (AI) and Machine Learning: AI and machine learning technologies are increasingly being used in drug design and modification. These technologies can analyze large datasets to identify new drug targets, predict drug interactions, and optimize drug properties, leading to faster and more efficient drug development processes.
- 3D Printing and Personalized Dosage Forms: 3D printing technology has the potential to revolutionize drug manufacturing by enabling the production of personalized dosage forms tailored to individual patient needs. This could lead to improved drug delivery and patient compliance.
- Nanotechnology: Nanotechnology offers new opportunities for drug modification by enabling the development of nanoscale drug delivery systems. These systems can improve drug solubility, stability, and targeting, leading to more effective and targeted drug therapies.
- Natural Products and Traditional Medicines: There is a growing interest in exploring natural products and traditional medicines for drug modification. These sources offer a vast array of chemical compounds that could be modified or optimized for therapeutic use.
Overall, the future of drug modification holds great promise, with advancements in precision medicine, targeted therapies, AI and machine learning, and other technologies offering new opportunities for developing safer, more effective, and personalized treatments for a wide range of diseases.
Bioinformatics tools
Bioinformatics tools play a crucial role in analyzing and interpreting biological data. These tools are computer programs designed to process and analyze biological information, such as DNA sequences, protein structures, and gene expression data. Here are some key points about bioinformatics tools:
- Variety of Tools: There are hundreds of bioinformatics tools available, each designed for specific tasks such as sequence alignment, gene prediction, and phylogenetic analysis.
- Freely Available: Many bioinformatics tools are freely available to researchers, making them accessible to a wide audience.
- Operating Systems: Bioinformatics tools are generally available on UNIX or LINUX operating systems, which are preferred for their stability and compatibility with scientific computing.
- Interaction with Databases: Bioinformatics tools often interact with bioinformatics databases, such as GenBank, SwissProt, and the Protein Data Bank, to access and retrieve biological data.
- Web Accessibility: Many bioinformatics tools are accessible via the World Wide Web, allowing researchers to use them without installing software on their own computers.
- Computational Requirements: Some bioinformatics tools require very powerful computers to run on, particularly those that involve complex calculations or large datasets.
- Computational Biology Research Group: Some institutions, such as the Computational Biology Research Group, provide environments for researchers to access and use bioinformatics tools and resources.
Overall, bioinformatics tools are essential for processing, analyzing, and interpreting biological data, and they play a critical role in advancing our understanding of the complexities of living organisms.
Bioinformatics tools are software applications and resources used to analyze and interpret biological data. These tools play a crucial role in a wide range of biological research areas, including genomics, proteomics, transcriptomics, and metabolomics. Here are some commonly used bioinformatics tools:
- Sequence Alignment Tools: Tools like BLAST, ClustalW, and MAFFT are used for pairwise and multiple sequence alignment, which helps in comparing and identifying similarities between biological sequences.
- Genome Assembly Tools: Tools like SPAdes, Velvet, and SOAPdenovo are used for assembling short DNA sequencing reads into longer contiguous sequences, aiding in the reconstruction of genomes.
- Gene Prediction Tools: Tools like GeneMark, Augustus, and Glimmer are used to predict the location and structure of genes within DNA sequences, helping in identifying coding regions.
- Phylogenetic Analysis Tools: Tools like MEGA, PhyML, and MrBayes are used for constructing phylogenetic trees, which help in understanding the evolutionary relationships between species.
- Structural Bioinformatics Tools: Tools like SWISS-MODEL, PyMOL, and MODELLER are used for predicting and visualizing the three-dimensional structures of proteins, RNA, and DNA.
- Functional Annotation Tools: Tools like InterProScan, DAVID, and GO-Elite are used for annotating biological sequences with functional information, aiding in the interpretation of sequence data.
- Next-Generation Sequencing (NGS) Analysis Tools: Tools like BWA, GATK, and Trinity are used for analyzing NGS data, including read alignment, variant calling, and de novo assembly.
- Network Analysis Tools: Tools like Cytoscape, STRING, and MetScape are used for analyzing and visualizing biological networks, such as protein-protein interaction networks and metabolic networks.
- Metagenomics Tools: Tools like QIIME, Mothur, and MG-RAST are used for analyzing metagenomic data, which involves studying genetic material recovered directly from environmental samples.
- Molecular Docking Tools: Tools like AutoDock, GOLD, and Vina are used for predicting the binding mode and affinity of small molecules to target proteins, aiding in drug discovery and design.
These are just a few examples of the many bioinformatics tools available to researchers. The field of bioinformatics is constantly evolving, with new tools and resources being developed to address the challenges of analyzing and interpreting biological data.
Bioinformatics tools can be categorized into several categories based on their primary functions. Here are some of the main categories:
- Homology and Similarity Tools: These tools are used to compare biological sequences (DNA, RNA, or protein) to identify similarities and infer evolutionary relationships. Examples include BLAST (Basic Local Alignment Search Tool) and FASTA.
- Protein Function Analysis: These tools are used to predict the function of proteins based on their sequence or structure. They can identify functional domains, predict protein-protein interactions, and infer biochemical pathways. Examples include InterProScan, Pfam, and STRING.
- Structural Analysis: These tools are used to analyze the three-dimensional structure of proteins and other biomolecules. They can predict protein structures, analyze protein-ligand interactions, and visualize molecular structures. Examples include PyMOL, Swiss-PdbViewer, and VMD (Visual Molecular Dynamics).
- Sequence Analysis: These tools are used to analyze DNA, RNA, and protein sequences. They can perform tasks such as sequence alignment, motif discovery, and phylogenetic analysis. Examples include ClustalW, MEGA (Molecular Evolutionary Genetics Analysis), and MEME (Multiple Em for Motif Elicitation).
These categories are not exhaustive, and there are many other types of bioinformatics tools available for various specialized tasks. The choice of tools depends on the specific research question and the type of biological data being analyzed.
Examples available Bioinformatics tools
Here are some examples of widely used bioinformatics tools:
- BLAST (Basic Local Alignment Search Tool): BLAST is a tool used for comparing gene and protein sequences against others in public databases. It can quickly identify sequences that are similar to a query sequence. BLAST comes in several types, including PSI-BLAST (Position-Specific Iterated BLAST), PHI-BLAST (Pattern Hit Initiated BLAST), and BLAST 2 sequences for comparing two sequences.
- FASTA: FASTA is a tool used for comparing a nucleotide or peptide sequence to a sequence database. It was one of the first widely used algorithms for database similarity searching. FASTA uses a heuristic method to find the best local alignments between the query sequence and sequences in the database.
- InterProScan: InterProScan is a tool used for protein sequence analysis. It combines different protein signature recognition methods into one resource, providing comprehensive information on the protein families, domains, and functional sites present in a protein sequence.
- ClustalW: ClustalW is a tool used for multiple sequence alignment. It aligns three or more sequences based on their similarity, allowing researchers to identify conserved regions and evolutionary relationships between sequences.
- NCBI Entrez: NCBI Entrez is a suite of search and retrieval systems used to access a diverse set of biomedical databases, including nucleotide and protein sequences, gene expression data, and 3D protein structures. It provides a comprehensive resource for accessing and analyzing biological data.
- Phylogenetic Analysis Tools (e.g., MEGA): Phylogenetic analysis tools are used to reconstruct evolutionary relationships between organisms based on their genetic sequences. MEGA (Molecular Evolutionary Genetics Analysis) is one such tool that allows researchers to build phylogenetic trees and analyze genetic data.
These are just a few examples of the many bioinformatics tools available for various types of analyses. Each tool has its strengths and limitations, and researchers often use a combination of tools to address specific research questions in bioinformatics.
Here are some examples of widely used bioinformatics tools categorized based on their functionalities:
Sequence Analysis:
- BLAST (Basic Local Alignment Search Tool): A tool for comparing a query sequence against a database of sequences to find homologous sequences.
- ClustalW: A tool for multiple sequence alignment, which aligns three or more sequences to identify conserved regions.
- MEME (Multiple Em for Motif Elicitation): A tool for discovering motifs (short, recurring patterns) in a group of related DNA or protein sequences.
Genome Analysis:
- NCBI Genome Data Viewer: A web-based tool for visualizing and analyzing genome assemblies and annotations.
- UCSC Genome Browser: A tool for viewing and analyzing annotated genome sequences from a variety of organisms.
Protein Structure Prediction:
- SWISS-MODEL: A tool for homology modeling, which predicts the three-dimensional structure of a protein based on its similarity to known protein structures.
- Phyre2: A tool for protein structure prediction and analysis using homology modeling and ab initio methods.
Metagenomics:
- QIIME (Quantitative Insights Into Microbial Ecology): A tool for analyzing microbial communities in environmental samples using high-throughput sequencing data.
- MetaPhlAn: A tool for profiling the composition of microbial communities from metagenomic shotgun sequencing data.
Next-Generation Sequencing (NGS) Analysis:
- BWA (Burrows-Wheeler Aligner): A tool for aligning short DNA sequencing reads to a reference genome.
- GATK (Genome Analysis Toolkit): A toolkit for variant discovery and genotyping using NGS data.
- DESeq2: A tool for differential gene expression analysis using RNA-seq data.
- Cufflinks: A tool for transcript assembly, differential expression, and regulation analysis using RNA-seq data.
Functional Annotation:
- InterProScan: A tool for annotating protein sequences with functional information, such as protein domains and families.
- DAVID (Database for Annotation, Visualization, and Integrated Discovery): A tool for functional annotation and enrichment analysis of gene lists.
These are just a few examples of the many bioinformatics tools available for various types of analyses in biological research. Each tool has its strengths and limitations, and the choice of tool depends on the specific analysis and research question being addressed.
Internet and search engines
The internet is a global network of interconnected computers and networks that allows for the transmission and sharing of information. Here are some key points about the internet and search engines:
- Network of Networks: The internet is often described as a “network of networks” because it is composed of thousands of interconnected local and regional networks in over 100 countries. These networks are connected through various technologies, including fiber optics, satellites, and wireless connections.
- Transmission Control Protocol (TCP) and Internet Protocol (IP): TCP/IP is the set of protocols that enables the connection and communication between different networks on the internet. TCP ensures that data is transmitted reliably and in the correct order, while IP is responsible for addressing and routing data packets to their destination.
- IP Address: An IP address is a unique numerical label assigned to each device connected to a computer network that uses the IP for communication. It serves as an identifier for the device and allows it to communicate with other devices on the internet. An IP address is usually made up of four numbers separated by periods, each of which refers to the domain, subnet, and the machine.
- Internet Service Provider (ISP): An ISP is an organization that provides access to the internet. ISPs typically offer a range of services, including internet connectivity, email, web hosting, and domain registration. Users can arrange internet access through an ISP, which connects them to the internet backbone.
- Search Engines: Search engines are tools that allow users to search for information on the internet. They use algorithms to index and rank web pages based on their relevance to a user’s query. Popular search engines include Google, Bing, and Yahoo, which provide access to a vast amount of information available on the internet.
Overall, the internet and search engines have transformed the way we access and share information, making it easier than ever to find information on virtually any topic.
Here is a list of useful websites for bioinformatics research:
- NCBI (National Center for Biotechnology Information): Provides access to a variety of biological databases, including GenBank, PubMed, and BLAST.
- Ensembl: Provides genome information for vertebrate genomes, including gene annotation and comparative genomics.
- UniProt: A comprehensive resource for protein sequence and annotation data.
- ExPASy: A bioinformatics resource portal that provides access to a variety of databases and analytical tools for proteins.
- EMBL-EBI (European Bioinformatics Institute): Provides access to a wide range of bioinformatics databases and tools, including EMBL-EBI’s own resources as well as those from external collaborators.
- PDB (Protein Data Bank): Provides access to 3D structural data of biological macromolecules.
- KEGG (Kyoto Encyclopedia of Genes and Genomes): Provides a comprehensive resource for understanding high-level functions and utilities of the biological system, such as the cell, the organism, and the ecosystem, from molecular-level information.
- STRING: A database of known and predicted protein-protein interactions.
- GeneCards: A database of human genes, their products, and their involvement in diseases.
- DAVID (Database for Annotation, Visualization, and Integrated Discovery): Provides a comprehensive set of functional annotation tools for investigators to understand the biological meaning behind large lists of genes.
These websites offer a wealth of information and tools for bioinformatics research, covering a wide range of topics from genomics to protein structure and function.
Related posts:
![cancer-omicstutorials]()
Recent Advancements in Bioinformatics for Cancer Research
A.I![error in database]()
Data errors in Bioinformatics databases
bioinformatics![bioinformatics, IT, computer, biology]()
Step-by-Step Guide: Calculating Sequence Lengths from a FASTA File
bioinformatics![biotech-bioinformatics-industry]()
Introduction to sequence annotation and functional prediction
bioinformatics![biochemistry-bioinformatics]()
Chemistry Fundamentals for Bioinformatics
bioinformatics![Visualization techniques for biological data]()
Biology Fundamentals for Bioinformatics
bioinformatics![bigdatainbiology-omicstutorials]()
Exploring Big Data in Bioinformatics: A Comprehensive Guide
bioinformatics![technology services for bioinformatics and genomics]()
Why Healthcare APIs Are Critical for the Future
Guides![Visualization techniques for biological data]()
How to detect gene fusions bioinformatically in RNA-sequencing data?
bioinformatics![bioinformatics free online courses]()
Building Bioinformatics Tools with Python
bioinformatics![engineeringgraphics]()
Engineering Graphics and Design
bioinformatics![herapeutic Potential of Long Non-coding RNAs]()
DNA Compression Algorithms
A.I![ChatGPT in healthcare and scientific applications]()
Artificial Intelligence in Rare Disease Diagnosis
A.I![pucbchem]()
Using PubChem to explore compound-protein interactions
bioinformatics![google-gemini-ultra-pro-nano-ai-model]()
Gemini 2.0: Ushering in the Agentic Era of AI Innovation
bioinformatics![Artificial_Intelligence__AI__Machine_Learning_-_Deeplearning]()
Deep Learning for Precision Medicine - How AI is Revolutionizing Bioinformatics
A.I
















