

Introduction to basic biological concepts
March 9, 2024Introduction to proteomics
Definition of proteomics
Proteomics is the large-scale study of proteins, particularly their structures and functions. It involves the identification, characterization, and quantification of all the proteins present in a biological system, such as a cell, tissue, or organism, at a given time. Proteomics aims to understand the roles proteins play in biological processes, how they interact with each other and other molecules, and how their functions are regulated.
Importance of studying proteins
Studying proteins is crucial for several reasons:
- Understanding Biological Processes: Proteins are essential for the structure, function, and regulation of cells, tissues, and organs. Studying proteins helps us understand how biological processes work at the molecular level.
- Disease Mechanisms: Many diseases, including cancer and neurological disorders, are linked to protein dysfunction. Understanding the role of proteins in these diseases can lead to the development of new diagnostic tools and therapies.
- Drug Discovery and Development: Proteins are targets for many drugs. Studying proteins helps identify potential drug targets and develop new drugs that can modulate protein function.
- Biotechnology and Industry: Proteins are used in various biotechnological processes, such as the production of enzymes, vaccines, and therapeutic proteins. Studying proteins helps improve these processes.
- Personalized Medicine: Proteomics can help identify biomarkers for disease diagnosis, prognosis, and treatment response, leading to personalized medicine approaches.
- Evolutionary Biology: Studying proteins can provide insights into the evolutionary relationships between different species and how proteins have evolved to perform different functions.
Overall, studying proteins is essential for advancing our understanding of biology, improving healthcare, and developing new technologies.
Brief history of proteomics
The field of proteomics has evolved over several decades:
- Early Studies (1970s-1990s): Early studies focused on individual proteins or small groups of proteins. Techniques such as SDS-PAGE (sodium dodecyl sulfate polyacrylamide gel electrophoresis) and Western blotting were used to separate and identify proteins.
- Introduction of Mass Spectrometry (1990s): The development of mass spectrometry (MS) revolutionized proteomics. MS allows for the identification and quantification of proteins in complex mixtures. Techniques such as MALDI-TOF (matrix-assisted laser desorption/ionization time-of-flight) and ESI (electrospray ionization) were key advancements.
- High-Throughput Techniques (2000s): The 2000s saw the development of high-throughput proteomics techniques, such as shotgun proteomics and protein microarrays. These techniques allowed for the rapid analysis of large numbers of proteins.
- Functional Proteomics (2010s): The focus shifted towards functional proteomics, which aims to understand the functions of proteins and their interactions within biological systems. This includes techniques such as protein-protein interaction studies and post-translational modification analysis.
- Current Trends: Current trends in proteomics include the integration of proteomics with other omics disciplines (such as genomics and metabolomics) to provide a more comprehensive understanding of biological systems. There is also a focus on single-cell proteomics and the development of bioinformatics tools for data analysis.
Throughout its history, proteomics has played a crucial role in advancing our understanding of biological systems and has led to numerous discoveries in areas such as disease mechanisms, drug development, and personalized medicine.
Basic Concepts
What is a protein?
Proteins are indeed large, organic molecules made up of smaller molecules called amino acids. They are the active elements of cells and play crucial roles in various biological processes. While small proteins can contain as few as 50 amino acids, they are typically much larger, consisting of hundreds or even thousands of amino acids. The specific sequence of amino acids in a protein determines its structure and function.
A protein is a large biomolecule made up of amino acids that are arranged in a specific sequence. Proteins are essential for the structure, function, and regulation of the body’s cells, tissues, and organs. They perform a wide variety of functions, including:
- Enzymatic: Proteins act as enzymes, catalyzing biochemical reactions in the body.
- Structural: Proteins provide structure and support to cells and tissues.
- Transport: Proteins transport molecules, such as oxygen, nutrients, and waste products, throughout the body.
- Hormonal: Proteins serve as hormones, regulating various physiological processes.
- Defense: Proteins are involved in the immune response, helping to defend the body against pathogens.
- Contractile: Proteins are responsible for muscle contraction and movement.
- Storage: Proteins can store molecules, such as iron or oxygen, for later use.
Proteins are encoded by genes and are synthesized in cells through a process called protein biosynthesis. The sequence of amino acids in a protein is determined by the sequence of nucleotides in the gene that encodes it. Alterations in protein structure or function can lead to various diseases and disorders.
Functions of proteins in living organisms
Proteins play a wide variety of essential roles in living organisms:
- Enzymatic Functions: Proteins act as enzymes, catalyzing biochemical reactions in cells. Enzymes are involved in processes such as digestion, metabolism, and DNA replication.
- Structural Support: Proteins provide structural support to cells and tissues. For example, collagen is a protein that provides strength and elasticity to skin, bones, tendons, and other connective tissues.
- Transportation: Proteins transport molecules such as oxygen (hemoglobin), ions, and other substances across cell membranes and throughout the body.
- Hormones: Some proteins act as hormones, which are chemical messengers that regulate various physiological processes, including growth, development, metabolism, and reproduction. Examples include insulin and growth hormone.
- Immune Response: Proteins are essential for the immune system. Antibodies, for example, are proteins produced by the immune system that recognize and bind to specific foreign molecules (antigens), marking them for destruction by other immune cells.
- Muscle Contraction: Proteins such as actin and myosin are responsible for muscle contraction. These proteins interact to generate the force needed for muscles to contract and produce movement.
- Storage and Transport of Molecules: Proteins can store and transport molecules within cells and throughout the body. For example, ferritin stores iron in a non-toxic form in cells, and albumin transports various molecules in the bloodstream.
- Signaling: Proteins are involved in cell signaling pathways, which regulate processes such as cell growth, differentiation, and death. Signaling proteins transmit signals from the cell surface to the nucleus, where they can alter gene expression.
- Regulation of Gene Expression: Proteins called transcription factors regulate the expression of genes by binding to specific DNA sequences and controlling the transcription of RNA from those genes.
- Catalyzing Metabolic Reactions: Proteins are involved in metabolic pathways, where they catalyze chemical reactions that are necessary for the breakdown of molecules for energy or the synthesis of complex molecules needed by the cell.
These are just a few examples of the diverse functions that proteins perform in living organisms. Proteins are essential for the structure, function, and regulation of cells, tissues, and organs, and they are involved in virtually every biological process in the body.
Diversity of protein functions
Proteins exhibit a remarkable diversity of functions, reflecting their importance in virtually all biological processes. Some key categories of protein functions include:
- Enzymatic Activity: Proteins act as enzymes, catalyzing a wide range of biochemical reactions. Enzymes can facilitate the breakdown of nutrients, the synthesis of essential molecules, and the conversion of one molecule into another.
- Structural Support: Proteins provide structural support to cells and tissues. For example, proteins like collagen form the structural framework of connective tissues, while keratin provides strength to hair, skin, and nails.
- Transport and Storage: Proteins are involved in the transport of molecules such as oxygen (hemoglobin), ions, and other substances across cell membranes and throughout the body. Proteins can also serve as storage molecules for essential nutrients and molecules.
- Hormonal Regulation: Proteins act as hormones, which are chemical messengers that regulate various physiological processes. For example, insulin regulates glucose metabolism, while growth hormone regulates growth and development.
- Immune Response: Proteins play a critical role in the immune response. Antibodies, for example, are proteins produced by the immune system that recognize and neutralize foreign invaders such as viruses and bacteria.
- Muscle Contraction: Proteins such as actin and myosin are responsible for muscle contraction. These proteins interact to generate the force needed for muscles to contract and produce movement.
- Signaling: Proteins are involved in cell signaling pathways, which regulate processes such as cell growth, differentiation, and death. Signaling proteins transmit signals from the cell surface to the nucleus, where they can alter gene expression.
- Regulation of Gene Expression: Proteins called transcription factors regulate the expression of genes by binding to specific DNA sequences and controlling the transcription of RNA from those genes.
- Catalyzing Metabolic Reactions: Proteins are involved in metabolic pathways, where they catalyze chemical reactions that are necessary for the breakdown of molecules for energy or the synthesis of complex molecules needed by the cell.
These examples highlight the diverse roles that proteins play in living organisms. Proteins are essential for the structure, function, and regulation of cells, tissues, and organs, and they are involved in virtually every biological process in the body.
Peptides
Peptides are short chains of amino acids linked together by peptide bonds. They are smaller than proteins and typically contain fewer than 50 amino acids, although this can vary. Peptides play several important roles in proteomics:
- Identification of Proteins: Peptides are often used in proteomics for the identification of proteins. Proteins can be digested into peptides using enzymes such as trypsin, and the resulting peptides can then be analyzed using techniques like mass spectrometry. The peptide sequences can be used to identify the corresponding proteins in a database.
- Quantification of Proteins: Peptides can also be used for the quantification of proteins in proteomics. By measuring the abundance of specific peptides, researchers can estimate the abundance of the corresponding proteins in a sample.
- Biomarker Discovery: Peptides are used in biomarker discovery, where specific peptides or patterns of peptides in biological samples are identified as indicators of certain diseases or physiological conditions.
- Protein-Protein Interactions: Peptides can be used to study protein-protein interactions. Short peptides corresponding to specific binding sites on proteins can be synthesized and used to disrupt or mimic protein-protein interactions in vitro.
Overall, peptides play a crucial role in proteomics by serving as tools for the identification, quantification, and study of proteins and their functions.
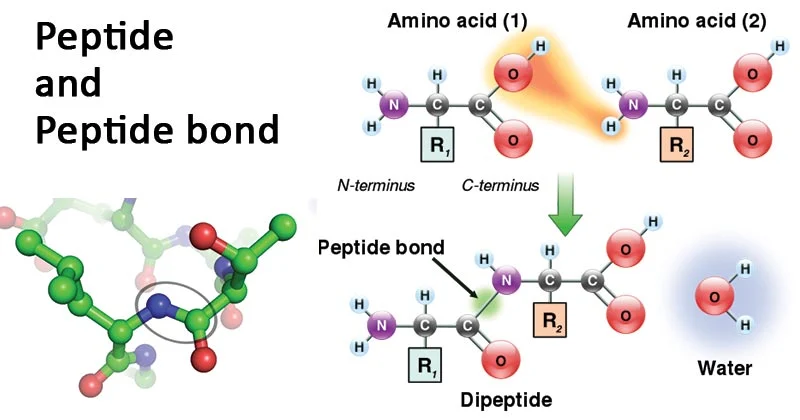
Peptide bonds
Peptide bonds are covalent bonds that link amino acids together in proteins. They are formed through a dehydration synthesis (condensation) reaction between the amino group (-NH2) of one amino acid and the carboxyl group (-COOH) of another amino acid, with the loss of a water molecule. This reaction forms a peptide bond, joining the two amino acids and releasing a molecule of water.
Peptide bonds are essential for the structure and function of proteins. They link amino acids in a specific sequence to form the primary structure of a protein. The sequence of amino acids, determined by the genetic code, dictates the overall structure and function of the protein. Peptide bonds also contribute to the secondary structure of proteins, such as alpha helices and beta sheets, which are stabilized by hydrogen bonds along the peptide backbone. Additionally, peptide bonds play a role in the tertiary and quaternary structures of proteins, contributing to the overall folding and stability of the protein molecule.
A peptide bond is a specialized type of amide bond that forms between two molecules when the α-carboxyl group of one molecule reacts with the α-amino group of another molecule, resulting in the release of a water molecule. This process, known as condensation, leads to the formation of a covalent bond between two amino acids, creating a peptide chain. Peptide bonds are also referred to as isopeptide bonds when the amide bond forms between the carboxyl group of one amino acid and the amino group of another amino acid at positions other than the alpha position. The presence of a partial double bond between the carbon and nitrogen of the amide bond stabilizes the peptide bond, with the nitrogen donating its lone pair to the carbonyl group, leading to a resonance effect. This resonance structure helps stabilize the bond but restricts rotation around the amide bond due to the partial double bond. Peptide bonds have a planar configuration and exhibit minimal movement around the C-N bond, while the single bonds on either side of the C-N bond display a high degree of rotational motion.
Amino Acids
Amino acids are organic compounds that serve as the building blocks of proteins. They contain an amino group (-NH2), a carboxyl group (-COOH), and a side chain (R group) attached to a central carbon atom. The side chain varies among different amino acids and determines their unique properties.
The role of amino acids as the building blocks of proteins is essential for life. Proteins are large, complex molecules that perform a wide variety of functions in living organisms, including:
- Structural Support: Proteins provide structural support to cells and tissues. For example, collagen is a protein that forms the structural framework of skin, bones, and other connective tissues.
- Enzymatic Activity: Proteins act as enzymes, catalyzing biochemical reactions in cells. Enzymes are essential for metabolism, DNA replication, and other cellular processes.
- Transport and Storage: Proteins transport molecules such as oxygen (hemoglobin), ions, and nutrients across cell membranes and throughout the body. Proteins can also serve as storage molecules for essential nutrients and molecules.
- Hormonal Regulation: Some proteins act as hormones, which are chemical messengers that regulate various physiological processes, including growth, metabolism, and reproduction.
- Immune Response: Proteins are involved in the immune response. Antibodies, for example, are proteins produced by the immune system that recognize and neutralize foreign invaders such as viruses and bacteria.
- Muscle Contraction: Proteins such as actin and myosin are responsible for muscle contraction. These proteins interact to generate the force needed for muscles to contract and produce movement.
- Signaling: Proteins are involved in cell signaling pathways, which regulate processes such as cell growth, differentiation, and death.
Overall, amino acids are essential for the synthesis of proteins, which are critical for the structure, function, and regulation of cells, tissues, and organs in living organisms.
General structure of amino acids
Amino acids have a general structure consisting of a central carbon atom (referred to as the α-carbon) bonded to four groups:
- Amino group (-NH2): This group contains a nitrogen atom bonded to two hydrogen atoms. It acts as a base, accepting a proton (H+) to become positively charged in acidic conditions.
- Carboxyl group (-COOH): This group contains a carbon atom double-bonded to an oxygen atom and single-bonded to a hydroxyl group (OH). It acts as an acid, donating a proton (H+) to become negatively charged in basic conditions.
- Hydrogen atom (H): This is a simple hydrogen atom bonded to the α-carbon.
- Side chain (R group): This is a variable group that differs among different amino acids. It determines the specific properties of the amino acid and can be as simple as a single hydrogen atom (in glycine) or as complex as a ring structure (in phenylalanine).
The general structure of an amino acid can be represented as:
H−N−C(R)−C(O)−OH
where:
- H is a hydrogen atom,
- N is a nitrogen atom,
- C is a carbon atom,
- R is the side chain specific to each amino acid, and
- O is an oxygen atom.
There are 20 standard amino acids that are commonly found in proteins, each with a unique side chain that gives it specific chemical and physical properties.

Classification of amino acids
Amino acids are classified based on their role in the body’s metabolism and whether the body can synthesize them or must obtain them from the diet. The classification includes:
- Essential Amino Acids: These are amino acids that cannot be synthesized by the body in sufficient quantities and must be obtained from the diet. There are nine essential amino acids for adults: histidine, isoleucine, leucine, lysine, methionine, phenylalanine, threonine, tryptophan, and valine.
- Non-Essential Amino Acids: These are amino acids that the body can synthesize from other compounds and do not need to be obtained from the diet. There are eleven non-essential amino acids: alanine, arginine, asparagine, aspartic acid, cysteine, glutamine, glutamic acid, glycine, proline, serine, and tyrosine.
- Conditionally Essential Amino Acids: These are amino acids that are normally non-essential but may become essential under certain conditions, such as during periods of illness or stress when the body’s demand for these amino acids exceeds its ability to produce them. Examples include arginine, cysteine, glutamine, tyrosine, glycine, ornithine, proline, and serine.
These classifications are important for understanding the dietary requirements of amino acids and ensuring that the body receives an adequate supply of all essential amino acids for protein synthesis and other biological functions.
Stereoisomerism in amino acids
Stereoisomerism in amino acids refers to the existence of two different spatial arrangements of atoms around the asymmetric carbon (the α-carbon) in the amino acid’s structure. This results in two different forms of the amino acid known as enantiomers, which are mirror images of each other and cannot be superimposed on each other.
In the case of amino acids, the α-carbon is bonded to four different groups: the amino group (-NH2), the carboxyl group (-COOH), a hydrogen atom (H), and the side chain (R group). The exception is glycine, where the α-carbon is bonded to two hydrogen atoms, making it achiral (not having stereoisomers).
The two forms of stereoisomers of amino acids are referred to as L-amino acids and D-amino acids. In living organisms, L-amino acids are predominantly found and are the building blocks of proteins. D-amino acids are less common in proteins but can be found in some peptides and are important in certain physiological processes.
The stereochemistry of amino acids is critical for their biological function, as enzymes and other proteins typically recognize and interact specifically with L-amino acids. The chirality of amino acids also plays a role in the determination of protein structure and function, as well as in the synthesis of pharmaceuticals and other bioactive compounds.

Protein Structure
Levels of protein structure
Primary structure
The primary structure of a protein refers to the specific sequence of amino acids that make up the protein. It is the simplest level of protein structure and is determined by the sequence of nucleotides in the gene that encodes the protein. The primary structure of a protein is crucial because it determines the overall structure and function of the protein.
The sequence of amino acids in a protein is often depicted using a one-letter or three-letter code for each amino acid. For example, the one-letter code for alanine is “A” and the three-letter code is “Ala.” The sequence of amino acids in a protein is read from the N-terminus (the end with the free amino group) to the C-terminus (the end with the free carboxyl group).
The primary structure of a protein is important because it determines how the protein will fold into its secondary, tertiary, and quaternary structures, which in turn determine the protein’s function. Even a single change in the amino acid sequence can have significant effects on the protein’s structure and function, leading to diseases and other biological consequences.
Secondary structure
The secondary structure of a protein refers to the local folded structures that form within a polypeptide chain. These structures are stabilized primarily by hydrogen bonds between the amino acids in the chain. The two most common types of secondary structure are alpha helices and beta sheets.
- Alpha Helix: In an alpha helix, the polypeptide chain is coiled like a spring, with hydrogen bonds forming between the carbonyl group of one amino acid and the amino group of another amino acid that is four residues away along the chain. This results in a spiral structure. Alpha helices are common in proteins and are important for providing structural stability.
- Beta Sheet: In a beta sheet, the polypeptide chain folds back and forth, forming a sheet-like structure. The hydrogen bonds in a beta sheet form between adjacent strands of the polypeptide chain, rather than within the same strand as in an alpha helix. Beta sheets can be either parallel, with the strands running in the same direction, or antiparallel, with the strands running in opposite directions. Beta sheets are also common in proteins and contribute to their structural stability.
Other less common types of secondary structure include beta turns (or beta bends) and omega loops, which are involved in connecting different regions of a protein or reversing the direction of the polypeptide chain.
The secondary structure of a protein is important because it influences the overall three-dimensional structure of the protein, known as its tertiary structure. The secondary structure also plays a role in determining the protein’s function, as different structures can interact with other molecules and perform specific biological functions.
Tertiary structure
The tertiary structure of a protein refers to the overall three-dimensional arrangement of atoms in the protein molecule. It is determined by the interactions between amino acid side chains (R groups) and includes interactions such as hydrogen bonds, disulfide bonds, hydrophobic interactions, and ionic bonds.
The tertiary structure is critical for the function of a protein because it determines the protein’s specific shape, which is essential for its biological activity. For example, enzymes must have a specific shape to bind to their substrates and catalyze reactions, and antibodies must have a specific shape to bind to antigens and mediate immune responses.
The tertiary structure of a protein is often depicted as a ribbon diagram or space-filling model, which shows the overall shape of the protein molecule. The tertiary structure can also include regions of secondary structure, such as alpha helices and beta sheets, as well as loops and other irregular structures.
Proteins can also have quaternary structure, which refers to the arrangement of multiple protein subunits (polypeptide chains) in a multi-subunit complex. The quaternary structure is stabilized by the same types of interactions as the tertiary structure and is important for the function of many proteins, including enzymes, antibodies, and hemoglobin.
Quaternary structure
The quaternary structure of a protein refers to the arrangement of multiple protein subunits (individual polypeptide chains) into a larger, functional protein complex. These subunits can be identical or different and are held together by various types of interactions, such as hydrogen bonds, disulfide bonds, hydrophobic interactions, and ionic bonds.
The quaternary structure is important for the function of many proteins, as it allows for the formation of larger, more complex structures with specialized functions. For example, hemoglobin, the protein responsible for transporting oxygen in the blood, is a quaternary protein complex consisting of four subunits, each containing a heme group that binds to oxygen.
Other examples of proteins with quaternary structure include antibodies, which are composed of two identical heavy chains and two identical light chains, and enzymes such as DNA polymerase, which can consist of multiple subunits that work together to catalyze biochemical reactions.
The quaternary structure of a protein is often stabilized by the same types of interactions that stabilize the tertiary structure, such as hydrogen bonds and hydrophobic interactions. Changes in the quaternary structure of a protein can affect its function and can be caused by factors such as changes in pH, temperature, or the presence of other molecules.

Importance of protein structure in function
The structure of a protein is critical for its function. The specific shape of a protein is essential for its interactions with other molecules, including other proteins, nucleic acids, and small molecules. Several key aspects of protein structure contribute to its function:
- Binding Specificity: The three-dimensional structure of a protein determines its ability to bind to specific molecules, such as substrates, ligands, or other proteins. Proteins have binding sites that are complementary in shape and charge to their binding partners, allowing for specific and selective interactions.
- Enzymatic Activity: The structure of an enzyme determines its catalytic activity. Enzymes have active sites with specific shapes that can bind to substrates and catalyze chemical reactions. The precise arrangement of amino acids in the active site is critical for the enzyme’s ability to catalyze a specific reaction.
- Regulation: Protein structure can be dynamic, allowing for conformational changes that regulate protein function. For example, the binding of a molecule to a protein can induce a conformational change that activates or inhibits its activity. Similarly, post-translational modifications can alter protein structure and function.
- Transport and Signaling: Proteins involved in transport, such as hemoglobin or ion channels, have specific structures that allow them to selectively transport molecules across membranes. Proteins involved in signaling, such as receptors, have structures that allow them to bind to signaling molecules and initiate cellular responses.
- Structural Support: Proteins provide structural support to cells and tissues. Proteins such as collagen form the extracellular matrix, providing strength and elasticity to tissues. Proteins like actin and tubulin form the cytoskeleton, providing structural support to cells and facilitating cell movement and division.
Overall, the structure of a protein is intimately linked to its function. Changes in protein structure, whether due to mutations, denaturation, or other factors, can have profound effects on protein function and can lead to diseases and disorders. Understanding protein structure is therefore crucial for understanding the molecular basis of health and disease.
Essential Amino Acids
Definition and importance in human diet
Amino acids are organic compounds that serve as the building blocks of proteins. They contain an amino group (-NH2), a carboxyl group (-COOH), a hydrogen atom, and a side chain (R group) attached to a central carbon atom. The side chain varies among different amino acids and determines their unique properties.
Amino acids are essential for human health and are crucial components of a balanced diet. They play several important roles in the body, including:
- Protein Synthesis: Amino acids are necessary for the synthesis of proteins, which are essential for the structure, function, and regulation of cells, tissues, and organs.
- Tissue Repair and Maintenance: Amino acids are required for the repair and maintenance of tissues, including muscles, skin, and organs.
- Enzyme and Hormone Production: Amino acids are involved in the production of enzymes and hormones, which are essential for various physiological processes in the body.
- Immune Function: Amino acids are important for the proper functioning of the immune system, helping to protect the body against infections and diseases.
- Neurotransmitter Synthesis: Some amino acids are precursors to neurotransmitters, which are chemical messengers that transmit signals in the brain and nervous system.
- Energy Production: Amino acids can be used as a source of energy when carbohydrates and fats are not available.
There are 20 standard amino acids that are commonly found in proteins, and they can be classified as essential, non-essential, or conditionally essential based on whether the body can synthesize them or must obtain them from the diet. Essential amino acids must be obtained from the diet because the body cannot synthesize them in sufficient quantities. Non-essential amino acids can be synthesized by the body, while conditionally essential amino acids are normally non-essential but may become essential under certain conditions, such as illness or stress.
A balanced diet that includes a variety of protein sources, such as meat, fish, poultry, eggs, dairy products, legumes, nuts, and seeds, can help ensure an adequate intake of essential amino acids and support overall health and well-being.
List of the 9 essential amino acids and their roles in the body
The nine essential amino acids are:
- Histidine: Required for the growth and repair of tissues, as well as for the production of histamine, a neurotransmitter involved in immune response, digestion, and sexual function.
- Isoleucine: Involved in muscle metabolism, immune function, and energy regulation. It is also important for hemoglobin formation.
- Leucine: Plays a key role in protein synthesis, muscle repair, and blood sugar regulation. It is also important for wound healing and growth hormone production.
- Lysine: Essential for growth and tissue repair, as well as for the production of enzymes, hormones, and antibodies. It is also important for calcium absorption and collagen formation.
- Methionine: Required for the synthesis of other amino acids, as well as for the production of proteins, hormones, and enzymes. It is also important for the metabolism of fats and the detoxification of heavy metals.
- Phenylalanine: Required for the production of neurotransmitters such as dopamine, norepinephrine, and epinephrine. It is also important for the synthesis of other amino acids and for the production of melanin, the pigment responsible for skin and hair color.
- Threonine: Essential for the growth and repair of tissues, as well as for the production of antibodies and enzymes. It is also important for the maintenance of proper protein balance in the body.
- Tryptophan: Precursor to serotonin, a neurotransmitter that regulates mood, sleep, and appetite. It is also important for the synthesis of niacin (vitamin B3) and for the production of proteins and enzymes.
- Valine: Plays a role in muscle metabolism, tissue repair, and energy production. It is also important for the maintenance of nitrogen balance in the body.
These essential amino acids cannot be synthesized by the body and must be obtained from the diet. They play important roles in various physiological processes and are crucial for overall health and well-being.
How do protein works?
Proteins work in a wide variety of ways to support the structure, function, and regulation of cells, tissues, and organs in the body. Some of the key ways in which proteins work include:
- Enzymatic Activity: Proteins act as enzymes, catalyzing biochemical reactions in the body. Enzymes facilitate chemical reactions by lowering the activation energy required for the reaction to occur. They can break down larger molecules into smaller ones (catabolic reactions) or build larger molecules from smaller ones (anabolic reactions).
- Structural Support: Proteins provide structural support to cells and tissues. For example, proteins such as collagen and elastin form the structural framework of skin, bones, tendons, and other connective tissues.
- Transportation: Proteins are involved in the transport of molecules such as oxygen (hemoglobin), ions, and nutrients across cell membranes and throughout the body. Proteins can also serve as storage molecules for essential nutrients and molecules.
- Hormonal Regulation: Some proteins act as hormones, which are chemical messengers that regulate various physiological processes. Hormones such as insulin and growth hormone regulate metabolism, growth, and development.
- Immune Response: Proteins are essential for the immune response. Antibodies, for example, are proteins produced by the immune system that recognize and neutralize foreign invaders such as viruses and bacteria.
- Muscle Contraction: Proteins such as actin and myosin are responsible for muscle contraction. These proteins interact to generate the force needed for muscles to contract and produce movement.
- Signaling: Proteins are involved in cell signaling pathways, which regulate processes such as cell growth, differentiation, and death. Signaling proteins transmit signals from the cell surface to the nucleus, where they can alter gene expression.
- Regulation of Gene Expression: Proteins called transcription factors regulate the expression of genes by binding to specific DNA sequences and controlling the transcription of RNA from those genes.
Overall, proteins are essential for virtually every biological process in the body. They are versatile molecules that can perform a wide variety of functions, making them crucial for maintaining health and supporting life.
How do genes code for proteins?
Genes code for proteins through a process called protein synthesis, which involves two main steps: transcription and translation.
- Transcription: In the cell nucleus, the DNA double helix unwinds and the enzyme RNA polymerase binds to a specific region of the gene called the promoter. RNA polymerase then synthesizes a single-stranded RNA molecule, called messenger RNA (mRNA), by adding complementary RNA nucleotides to the DNA template strand. The mRNA molecule is a copy of the gene’s DNA sequence, but with uracil (U) replacing thymine (T).
- Translation: The mRNA molecule leaves the nucleus and enters the cytoplasm, where it binds to a ribosome, a complex of RNA and proteins. Transfer RNA (tRNA) molecules, each carrying a specific amino acid, recognize and bind to specific sequences of three mRNA nucleotides called codons. The tRNA molecules bring their amino acids in the correct sequence dictated by the mRNA codons. The ribosome moves along the mRNA, reading the codons and catalyzing the formation of peptide bonds between the amino acids carried by the tRNA molecules. This process continues until a stop codon is reached, at which point the ribosome releases the newly synthesized protein.
The sequence of nucleotides in the DNA gene determines the sequence of amino acids in the protein. Each set of three nucleotides in the mRNA, called a codon, codes for a specific amino acid. There are 64 possible codons, but only 20 amino acids, so most amino acids are coded for by more than one codon (redundancy). Additionally, there are three “stop” codons that signal the end of protein synthesis.
In summary, genes code for proteins by first transcribing the DNA sequence into mRNA in the nucleus and then translating the mRNA sequence into a specific sequence of amino acids in the cytoplasm. This process is essential for the synthesis of proteins, which are critical for the structure, function, and regulation of cells and tissues in the body.
codon
A codon is a sequence of three nucleotides (either RNA or DNA) that corresponds to a specific amino acid or serves as a start or stop signal for protein synthesis. The genetic code is a set of rules that determines how codons are translated into amino acids.
There are 64 possible codons, but only 20 amino acids, so most amino acids are specified by more than one codon. For example, the codons GCU, GCC, GCA, and GCG all specify the amino acid alanine.
In addition to specifying amino acids, three codons—UAA, UAG, and UGA—serve as stop signals, indicating the end of protein synthesis. These codons do not code for any amino acid and are known as stop codons or termination codons.
The start codon, AUG, also codes for the amino acid methionine and serves as the initiation signal for protein synthesis. It marks the beginning of the mRNA sequence to be translated into a protein.
Codons are read sequentially along the mRNA molecule during translation. Each codon is recognized by a specific transfer RNA (tRNA) molecule carrying the corresponding amino acid, which adds the amino acid to the growing polypeptide chain.

This figure shows the genetic code for translating each nucleotide triplet in mRNA into an amino acid or a termination signal in a nascent protein.
DNA structure
DNA (deoxyribonucleic acid) is a double-stranded molecule that carries the genetic instructions for the development, functioning, growth, and reproduction of all known living organisms and many viruses. The structure of DNA was first described by James Watson and Francis Crick in 1953, based on X-ray diffraction data collected by Rosalind Franklin and Maurice Wilkins.
- Double Helix: DNA has a double helix structure, which consists of two long strands that are twisted around each other. The two strands are antiparallel, meaning they run in opposite directions. The helical structure is stabilized by hydrogen bonds between complementary bases on opposite strands.
- Nucleotides: Each strand of DNA is made up of nucleotides, which consist of a sugar molecule (deoxyribose), a phosphate group, and a nitrogenous base. There are four types of nitrogenous bases in DNA: adenine (A), thymine (T), cytosine (C), and guanine (G). Adenine pairs with thymine, and cytosine pairs with guanine, through hydrogen bonding, forming the rungs of the DNA ladder.
- Base Pairing: The base pairing between adenine and thymine (A-T) and between cytosine and guanine (C-G) is known as complementary base pairing. This base pairing is specific and allows DNA to be replicated accurately.
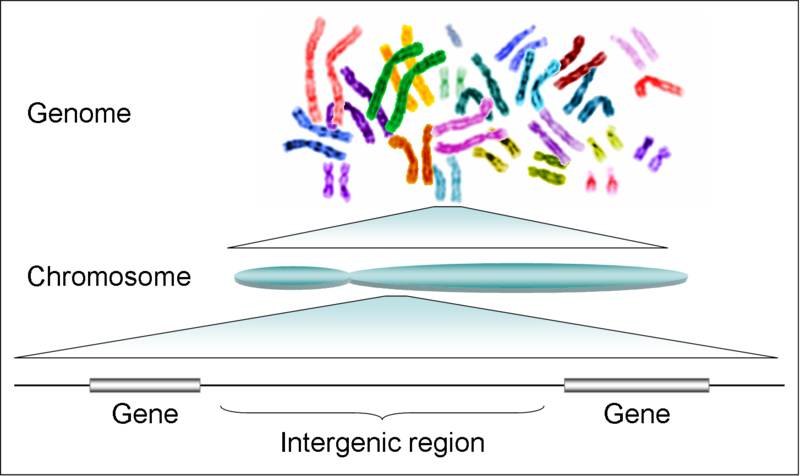
- Chromosomes: In eukaryotic cells, DNA is organized into structures called chromosomes, which are located in the cell nucleus. Each chromosome contains a single, long DNA molecule that is tightly coiled and condensed.
- Genes: Genes are specific sequences of DNA that contain the instructions for building proteins. Genes are located at specific positions on chromosomes and are transcribed into messenger RNA (mRNA), which is then translated into protein.
- Function: DNA carries the genetic information that determines an organism’s traits. This information is encoded in the sequence of nucleotides along the DNA molecule. DNA is responsible for inheritance, as it is passed from parents to offspring during reproduction.
In summary, DNA is a double-stranded molecule with a helical structure that carries genetic information. It is made up of nucleotides, which consist of a sugar, a phosphate group, and a nitrogenous base. DNA is organized into chromosomes and contains genes, which are the instructions for building proteins and determining an organism’s traits.

DNAStructure
nucleoside
A nucleoside is a molecule composed of a nitrogenous base (either adenine, cytosine, guanine, thymine, or uracil) linked to a sugar molecule (either ribose or deoxyribose) but without the phosphate group found in nucleotides. Nucleosides are the building blocks of nucleotides, which are the monomers that make up DNA and RNA.
The nitrogenous base in a nucleoside can be adenine (A), cytosine (C), guanine (G), thymine (T), or uracil (U), depending on whether the nucleoside is part of DNA or RNA. The sugar molecule in a nucleoside can be ribose or deoxyribose, depending on whether it is a ribonucleoside or a deoxyribonucleoside.
When a phosphate group is added to a nucleoside, it forms a nucleotide. Nucleotides are the monomers that make up the DNA and RNA polymers, which store and transmit genetic information in cells. The sequence of nucleotides in DNA and RNA determines the genetic code, which specifies the amino acid sequence of proteins and regulates gene expression.
nucleotide
A nucleotide is a molecule that serves as the basic building block of nucleic acids such as DNA and RNA. It is composed of three main components:
- Nitrogenous Base: This is a nitrogen-containing molecule that is responsible for the nucleotide’s base-pairing properties. In DNA, the nitrogenous bases are adenine (A), cytosine (C), guanine (G), and thymine (T). In RNA, thymine is replaced by uracil (U).
- Sugar Molecule: The sugar molecule in a nucleotide can be either ribose (in RNA) or deoxyribose (in DNA). The sugar is bonded to the nitrogenous base and provides the backbone structure of the nucleic acid.
- Phosphate Group: The phosphate group is attached to the sugar molecule and provides the negative charge in the nucleotide. It also allows for the formation of phosphodiester bonds, which link nucleotides together to form nucleic acid chains.
In DNA, nucleotides are linked together in a specific sequence to form a single strand, with each nucleotide connected to the next by phosphodiester bonds. The two strands of DNA are then held together by hydrogen bonds between complementary nitrogenous bases (A with T, and C with G) to form the double helix structure.
In RNA, nucleotides are also linked together in a specific sequence to form a single strand, but RNA is usually single-stranded and can fold into complex three-dimensional structures. RNA plays a variety of roles in the cell, including serving as a messenger molecule (mRNA) for protein synthesis, as well as in other cellular processes such as transcription, translation, and regulation of gene expression.

DNA backbones






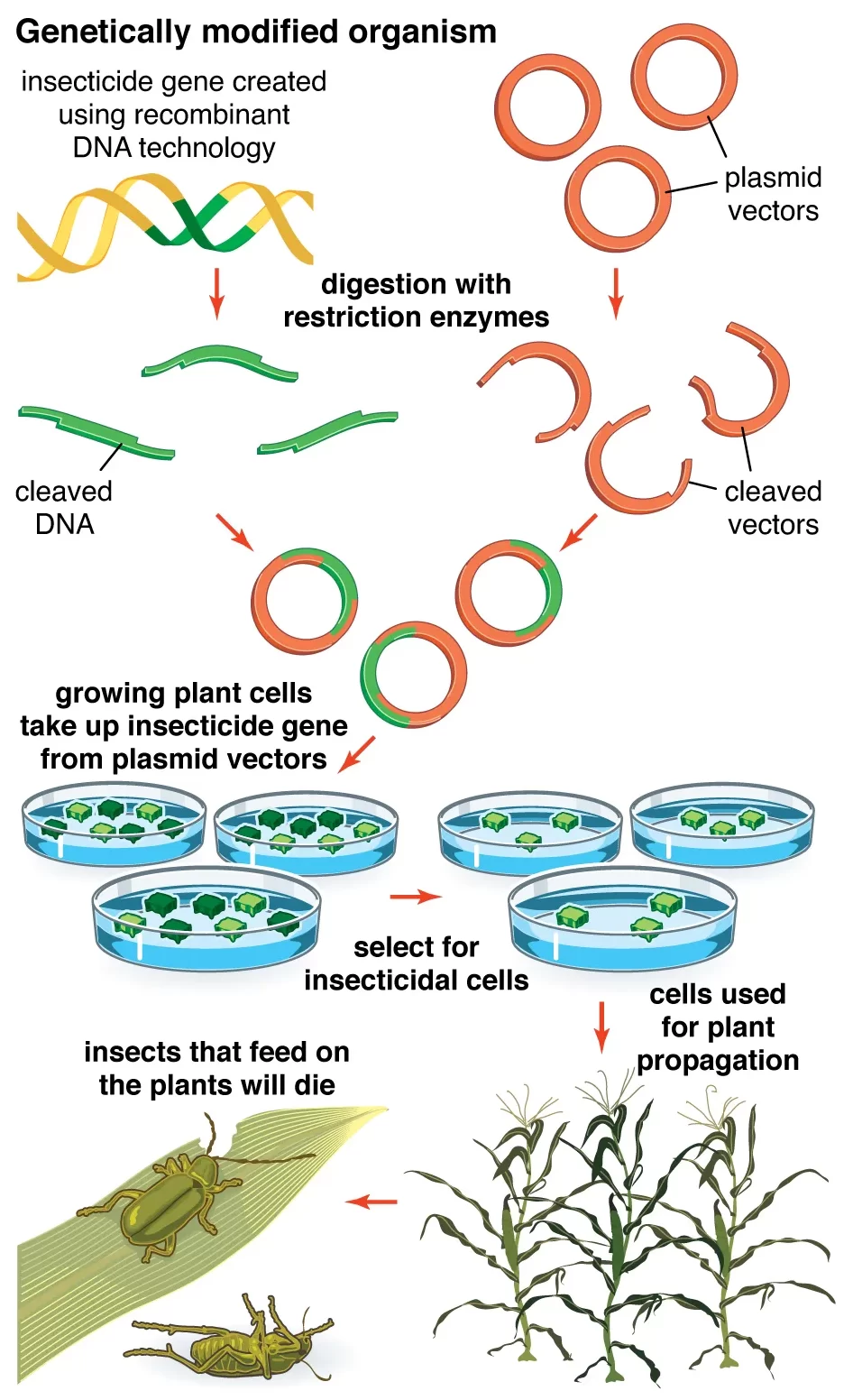
Related posts:
![NCBI-Bioinformatics]()
Understanding NCBI: A Beginner's Guide to Bioinformatics Tools and Resources
bioinformatics![bioinformatics software]()
2023's Comprehensive Guide to Choosing the Best Bioinformatics Software
bioinformatics![bioinformatics lab]()
Guide to Learning and Mastering Bioinformatics
bioinformatics![metabolomics]()
Unlocking the World of Proteomics Data Analysis: A Student's Guide
Guides![AI-bioinformatics]()
Should We Remove Duplicated Reads in RNA-Seq?
bioinformatics![Bioinformatics]()
Guide to Installing, Running, and Analyzing MD Simulations with GROMACS: A Practical Approach with P...
bioinformatics![python-bioinformatics-basics]()
Step-by-Step Guide: Removing Duplicate Sequences in FASTA Files
bioinformatics![dna-genes-chromosomes]()
Step-by-Step Guide to Changing Chromosome Notation in VCF Files
bioinformatics![data-science]()
A Guide to Using ChatGPT for Data Science Projects
A.I![Top 10 Python Machine Learning Tutorials to Excel in Bioinformatics]()
Comprehensive Bioinformatics Analysis Guide: From Data Acquisition to Advanced Predictive Modeling &...
bioinformatics![Next-Generation Sequencing (NGS) Instruments of 2023]()
Top Next-Generation Sequencing (NGS) Instruments of 2023: A Comparative Guide
bioinformatics![bioinformatics projects]()
The Future of Bioinformatics: Skills That Make Analysts Irreplaceable
bioinformatics![A Guide to Genomic Variant Calling Tools]()
A Guide to Genomic Variant Calling Tools
bioinformatics![bioinformatics-DNA, protein]()
Submitting High-Throughput Sequence Data to GEO (Gene Expression Omnibus)
bioinformatics![Guide to XML for biologists]()
XML in Bioinformatics: A Comprehensive Guide for Biologists
bioinformatics![AI-bioinformatics]()
Mapping SNPs to Pathways and Diseases
bioinformatics















